At a Glance
Coding agents struggle to coordinate: two-agent teams succeed only about 25% of the time—roughly half the success of a single agent doing both tasks.
ON THIS PAGE
What They Found
When given overlapping software tasks that require coordination, paired coding agents perform much worse than a single agent doing the same work. Allowing free-form chat between agents did not reliably improve outcomes. Failures trace to three gaps: poor or mistimed communication, breaking of commitments, and wrong assumptions about what the partner is doing, though rare successful runs show role splitting and negotiation can work. See the Consensus-Based Decision Pattern for structured coordination.
By the Numbers
1Two-agent cooperation success is about 25% for top models (GPT-5 and Claude Sonnet 4.5).
2A single agent doing both tasks (solo baseline) succeeds at roughly 50%, about double the paired result.
377.3% of CooperBench tasks contain code-level conflicts that require coordination to resolve.
What This Means
Engineers building tools that let multiple AI agents work together should care because current agents increase risk of broken integrations and wasted developer time. Technical leaders evaluating agent-based workflows should use CooperBench-style tests before deploying multi-agent pipelines. Researchers can use the benchmark to measure progress on agent-to-agent coordination and trust. Consider how Coding Assistants could guide tool development and evaluation.
Not sure where to start?Get personalized recommendations
Key Figures
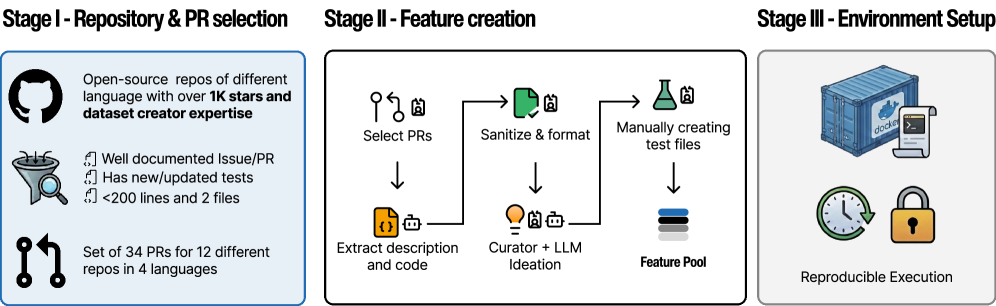
Fig 1: Figure 2: The CooperBench construction pipeline. Each task is carefully engineered by domain experts to ensure conflicts are realistic, resolvable, and representative of production software development challenges.
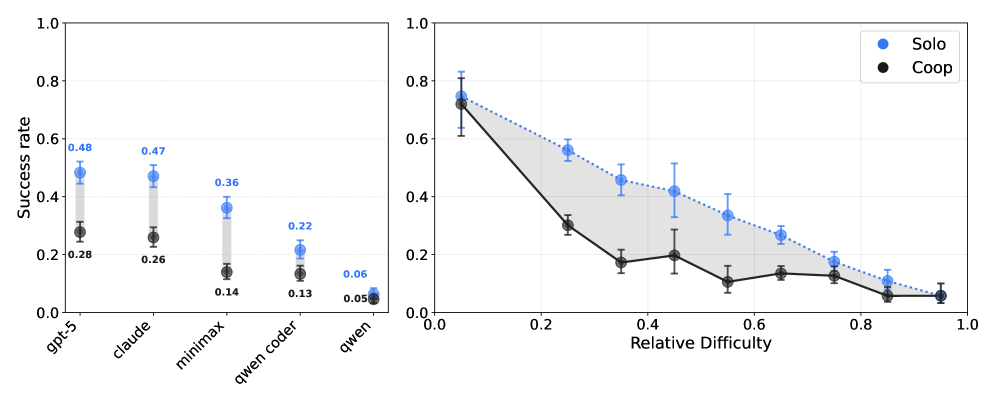
Fig 2: Figure 3: Left: Under Coop setting, agents with different foundation models perform significantly worse than how they perform under Solo setting, except for Qwen3-30B-A3B-Instruct-2507 , which performs bad under both settings. This Solo-Coop gap is what we call the “coordination gap”. Right: The relationship between tasks’ technical difficulties and Solo-Coop gap. The shaded area has a large middle section which shows that the coordination gap is larger for middle-level tasks than for tasks which are extremely easy or difficult.
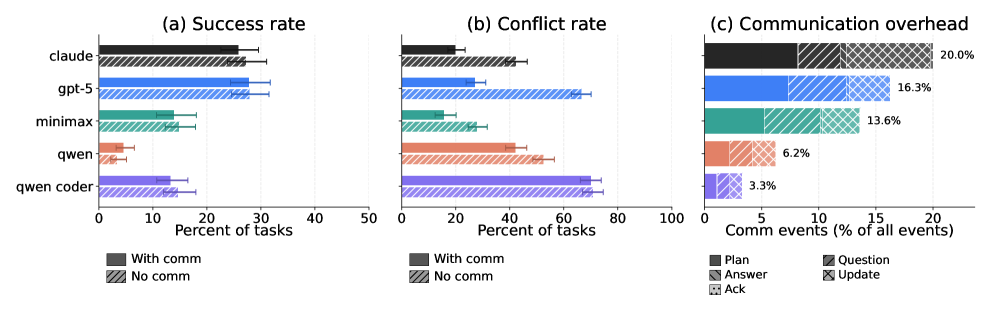
Fig 3: Figure 4: (a) Effect of inter-agent communication on cooperation success or lack thereof. All agents fail to use communication for improving cooperation success. (b) Communication substantially reduces naive merge conflicts across all models. (c) Communication overhead as a percentage of all execution events, broken down by message type. Models that communicate more (e.g., Claude Sonnet 4.5 , GPT-5 ) show larger reductions in conflict rate.
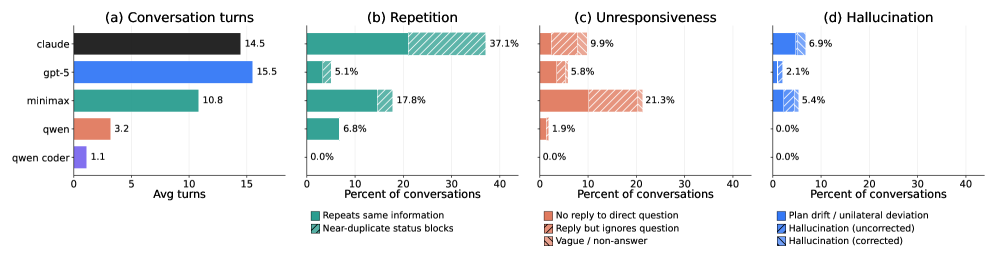
Fig 4: Figure 5: Break down frequencies of different kinds of communication errors.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Findings are specific to cooperative coding tasks with intentionally overlapping changes and may not generalize to fully scaffolded workflows or non-code domains. Experiments limited tool actions to local file and terminal operations and used a particular messaging setup; richer interfaces (screen sharing, shared signatures) could change results. Models and frameworks evolve quickly, so the coordination gap might shrink with targeted multi-agent training or verified commitment protocols. Address potential risks like Memory Poisoning.
Methodology & More
CooperBench is a new benchmark of 652 realistic software tasks (across Python, TypeScript, Go, and Rust) designed to test how well two coding agents can cooperate when their assigned features touch overlapping code. Each task assigns two features and unit tests; agents work in isolated containers, make file and terminal edits, and may exchange free-form natural language messages. Success is measured by whether the merged patch implements both features and passes tests. The dataset intentionally includes conflicts—77.3% of tasks require resolving overlapping changes—so successful outcomes demand true coordination, not independent work. Evaluating state-of-the-art models shows a large coordination gap: paired agents (cooperation mode) hit about 25% success while a single agent assigned both tasks achieves roughly 50%. Allowing messaging did not significantly raise overall success rates, even though messages reduced naive merge conflicts; agents nonetheless fail by sending vague or late messages, reneging on promises, or holding incorrect expectations about the partner’s edits. Still, occasional emergent behaviors—clear role division, resource splitting, and negotiated plans—do appear, suggesting coordination skills can be acquired. CooperBench is released as an open platform to measure and drive progress on multi-agent trust, verification of commitments, and training methods that reward cooperation under partial observability. Also notes that Tree of Thoughts Pattern and Chain of Thought Pattern concepts may inform future improvements in reasoning and planning.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
All authors have very low h-index values, no notable affiliations listed, and only an arXiv preprint with no citations — limited signals of established credibility.