At a Glance
Teams of AI agents usually underperform their best member because they average viewpoints instead of deferring to the expert; that averaging causes an 8–38% drop on hard benchmarks.
ON THIS PAGE
What They Found
When multiple large models discuss a problem without fixed roles, the team often fails to match its single best member. The main breakdown is not that teams can't spot the expert, but that they dilute expert answers through compromise. Bigger teams make the problem worse, yet the same consensus behavior makes teams resilient to a sabotaging member. consensus-based decision pattern
Not sure where to start?Get personalized recommendations
By the Numbers
1Relative synergy gaps ranged from 8.1% (MMLU Pro) to 37.6% (Humanity’s Last Exam benchmark), showing teams can fall far short of their best member.
2SimpleQA and MATH-500 teams showed 18.7% and 15.2% relative gaps respectively, confirming the effect across different benchmark types.
3Ranking error increases with team size (expertise dilution) and many results are statistically significant (p < 0.05 for dilution and compromise correlations).
What This Means
Engineers building multi-agent system and product leaders deciding how to combine models should care—out-of-the-box multi-agent discussion can reduce accuracy when one model is clearly better. Researchers and evaluators should add ‘can the team beat its best member?’ to their testing, and consider mechanisms that let agents defer to proven expertise rather than averaging.
Key Figures
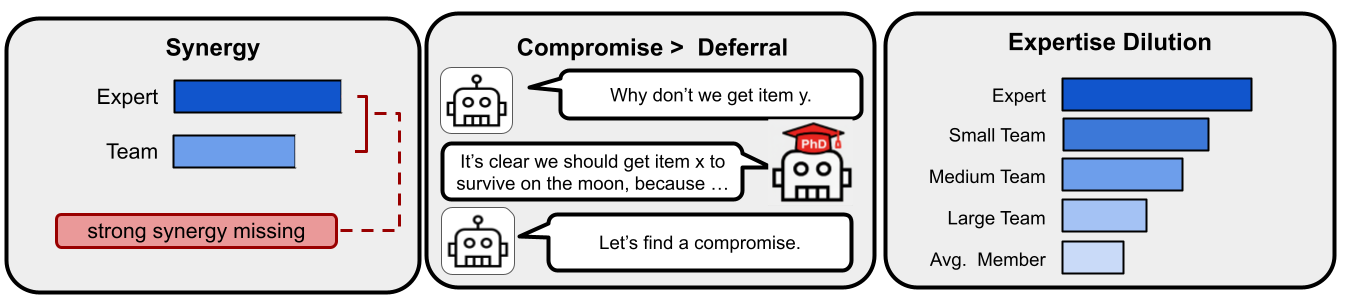
Fig 1: Figure 1 : Multi-agent teams fail to leverage expertise. Panel 1: Strong synergy. The bars show the performance of the team and the expert. The expert outperforming the team demonstrates the absence of strong synergy. Panel 2: Teams fail to leverage expertise and prioritize consensus. An illustrative conversation where the non-experts prioritize compromising over the expert’s opinion (denoted by the robot with a PhD cap). Panel 3: Larger teams perform worse. We observe that as team size increases, expertise dilution becomes more severe, with team performance further approaching the member average.
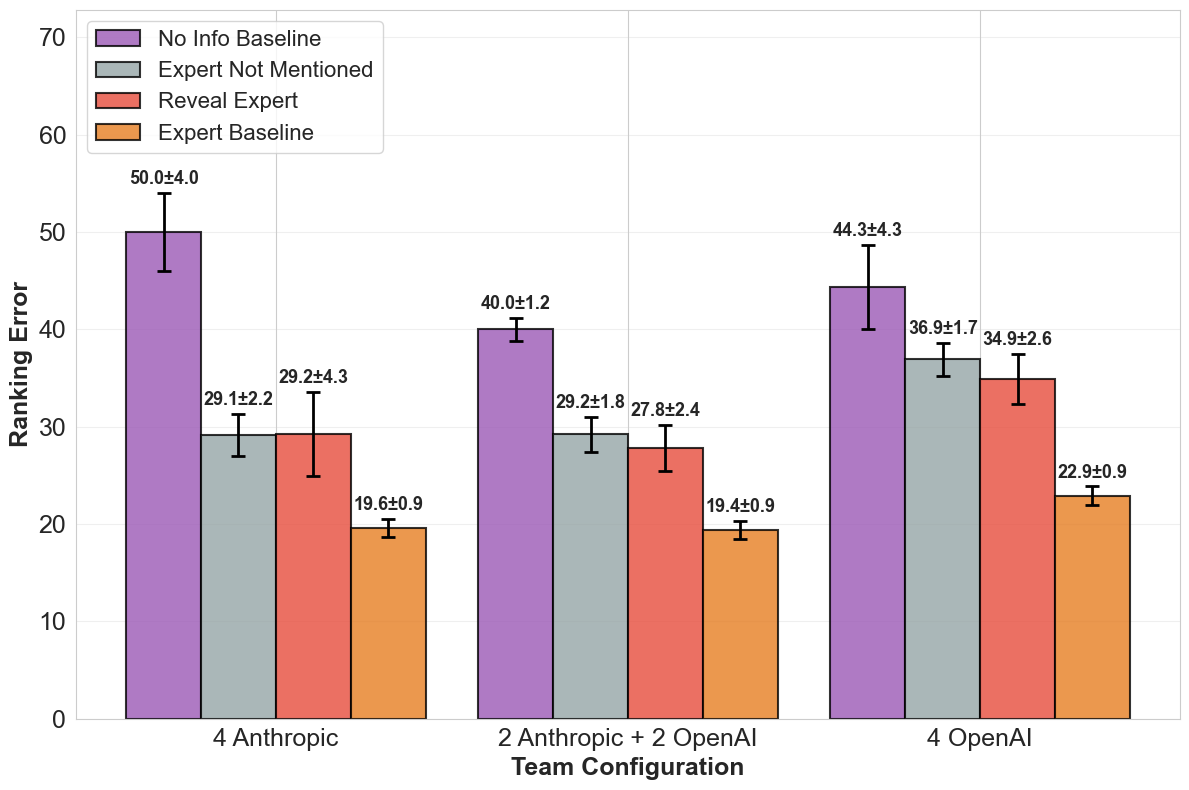
Fig 2: Figure 2 : Concentrated Expertise Performance: Lost at Sea. Teams fail to match expert performance even when explicitly told who the expert is using aggressively-tuned prompts. The minimal improvement from Expert Not Mentioned to Reveal Expert indicates that leveraging expertise is the primary bottleneck, not identification. This trend is robust across multiple team configurations: 4 Haiku-3.5, 2 Haiku-3.5 + 2 GPT-4o-mini, and 4 GPT-4o-mini. Performance measured by L1 distance from expert ranking (lower is better; 10 seeds per team configuration × \times information condition). Information conditions are defined in Section 3.3 . Results for all tasks and expertise distributions are provided in Appendix C .
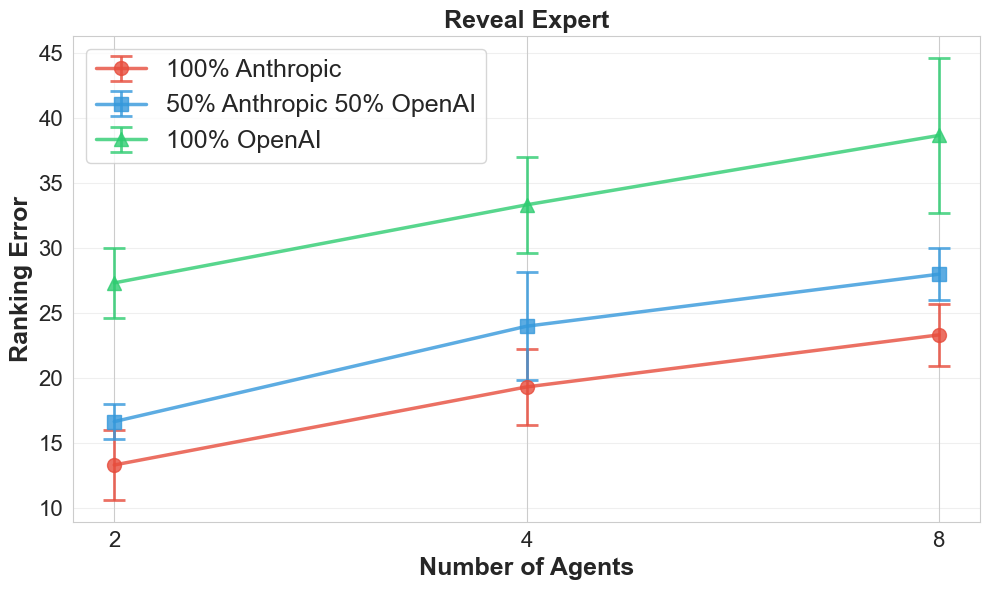
Fig 3: Figure 3 : Expertise Dilution Effect. NASA Moon Survival ( Reveal Expert condition) shows ranking error increasing with team size across all model compositions (100% Anthropic, 50/50 mixed, 100% OpenAI). The consistent upward trend demonstrates that expertise dilution is robust to team composition. Error bars are ± \pm SEM. Complete plots for all tasks in Appendix E .
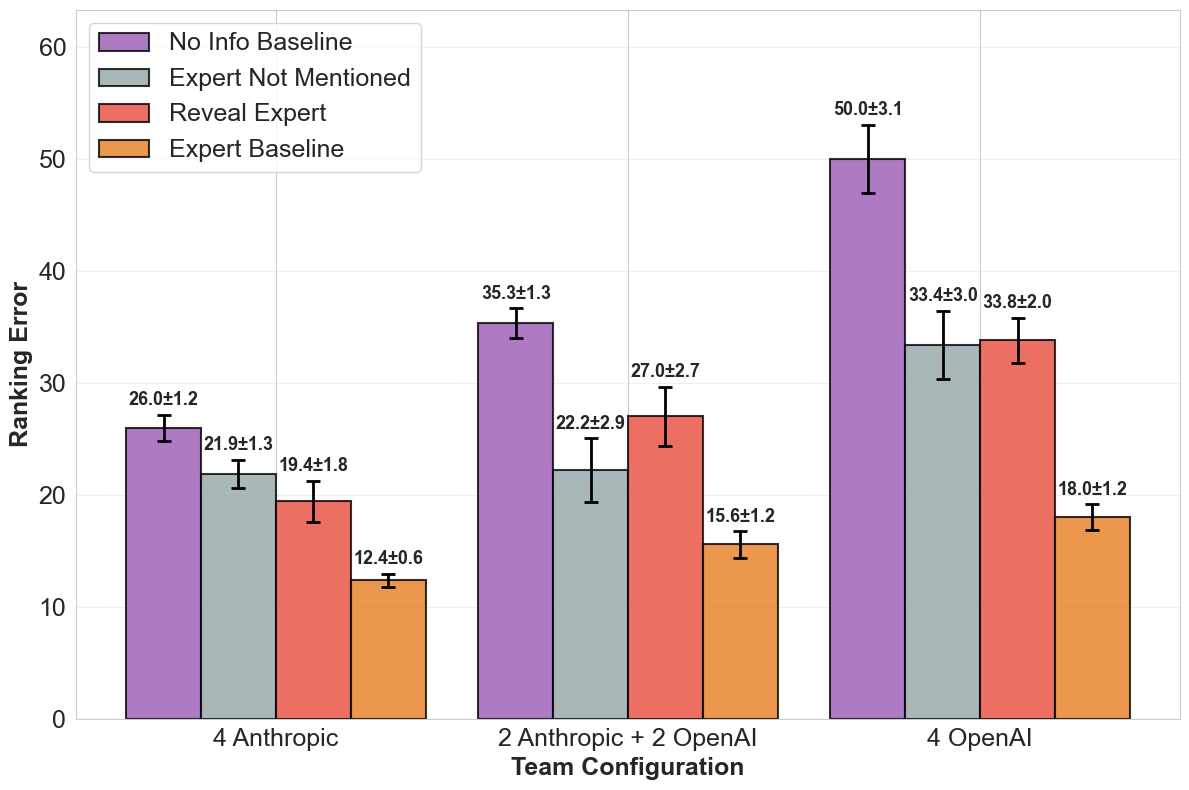
Fig 5: (a) Concentrated Expertise
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Experiments used four-agent teams and four rounds of discussion as a representative setting; results may vary with different team sizes, more rounds, or other interaction protocols. Models tested are frontier large language models; outcomes depend on how individual models were trained and aligned to be agreeable. The consensus behavior that harms accuracy also provides robustness to malicious or noisy team members, so fixing the problem may require careful trade-offs. For more on interaction planning, see the Planning Pattern.
Methodology & More
Teams of heterogeneous large language models were tested on classic group decision tasks (like Lost at Sea and NASA Moon Survival) and modern benchmarks (MMLU Pro, SimpleQA, GPQA Diamond, HLE, MATH-500). Teams of four models held four rounds of discussion; individual answers were collected before discussion to track how interaction changed outcomes. The study measures 'strong synergy'—whether a team matches or beats its single best member—strong synergy rather than merely beating the average member. Results show teams consistently fail strong synergy, underperforming the best individual by 8–38% across benchmarks. Controlled tests show teams can usually identify who the expert is, but they fail to leverage that expertise: conversations show integrative compromise (averaging expert and weaker views) rather than deference. Larger teams worsen this 'expertise dilution.' Paradoxically, the same tendency to average makes teams robust to adversarial members who are instructed to sabotage results, suggesting a trade-off between ability to exploit expertise and resistance to manipulation. expertise dilution. Practical next steps include building mechanisms for explicit deference, reputation signals, or structured protocols that let proven experts carry more weight without losing robustness to malicious inputs.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Mix of modest h-indices (several in mid single digits); some recognizable names but no top affiliations or venue.