At a Glance
AI agents using large language models avoid conflicts when they act in sequence but commonly deadlock when forced to decide at the same time; don’t assume agents will coordinate without an external rule or arbiter.
ON THIS PAGE
What They Found
A simple benchmark based on the Dining Philosophers problem shows current language models succeed almost perfectly when agents act in turn but fail frequently under simultaneous decision-making. Deadlock rates for top models ranged from 25% up to 95–100% depending on the setup. Allowing short, delayed messages between neighbors did not reliably help and sometimes made deadlock rates worse because agents announce intentions but then fail to act consistently. The root cause is convergent reasoning: independently smart agents pick the same “reasonable” action and end up conflicting when choices must be simultaneous. This mirrors Coordination Deadlock.
Not sure where to start?Get personalized recommendations
By the Numbers
1GPT-5.2: 0% deadlock in sequential mode; 25–95% deadlock in simultaneous mode across conditions.
2With 3 agents, simultaneous deadlock reached 95–100%; with 5 agents, simultaneous deadlock ranged 25–65%.
3Enabling neighbor communication raised deadlock in one case from 25% to 65%; message-action consistency was only 29–44%, so stated intentions were often not followed.
What This Means
Engineers building Multi-Agent System should treat simultaneous shared-resource decisions as high-risk and include explicit coordination (locks, leaders, or turn-taking). Technical leaders evaluating agent deployments should add tests like DPBench to pre-production validation to catch these failures before fielding. Researchers studying agent interactions can use the benchmark to track progress on true simultaneous coordination Consensus-Based Decision Pattern.
Key Figures
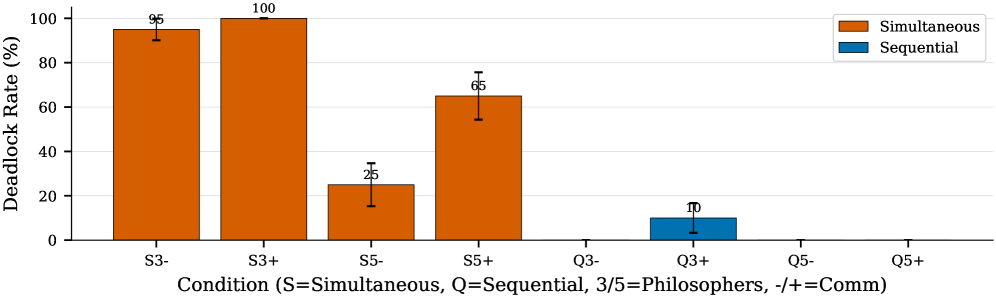
Fig 2: Figure 2 : GPT-5.2 deadlock rates across all eight DPBench conditions. Simultaneous mode (orange) produces dramatically higher deadlock rates than sequential mode (blue). The gap is most pronounced with 3 philosophers, where simultaneous mode reaches 95–100% deadlock while sequential mode stays near 0%.
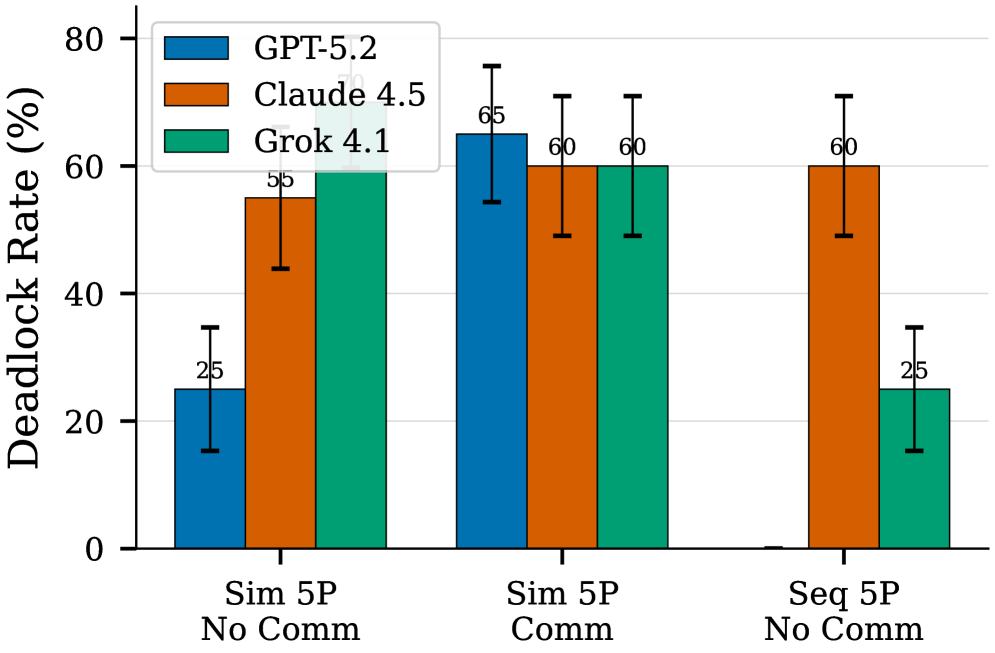
Fig 3: Figure 3 : Cross-model comparison of deadlock rates. GPT-5.2 (blue) achieves 0% deadlock in sequential mode, while Claude 4.5 (orange) and Grok 4.1 (green) still deadlock 60% and 25% of episodes respectively. All models struggle in simultaneous mode, with deadlock rates between 25–70%.
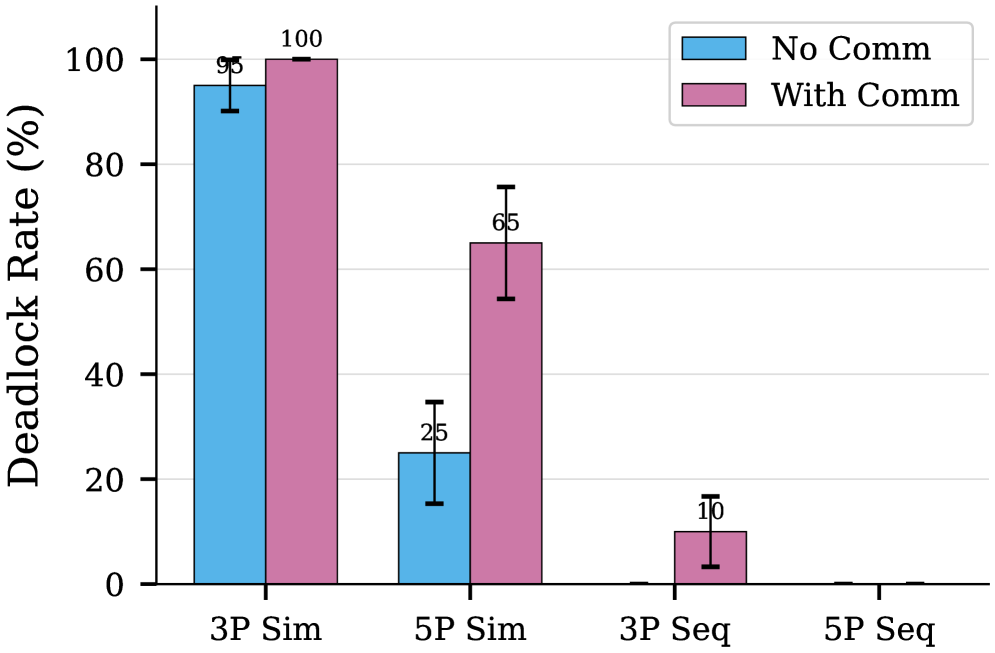
Fig 4: Figure 4 : Effect of communication on deadlock rates. Contrary to expectations, enabling communication (pink) often increases deadlock compared to no communication (blue). In simultaneous mode with 5 philosophers, deadlock rises from 25% to 65%. Sequential mode remains near 0% regardless of communication.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Results come from a stylized task (Dining Philosophers) with N=3 and N=5 and three model families; outcomes may differ on richer, domain-specific problems or larger teams. Only one prompt design and fixed timing (messages arrive one timestep late) were tested—alternate communication protocols or fine-tuning could improve coordination. The benchmark highlights a coordination failure mode (convergent reasoning) rather than proving all multi-agent setups will fail in practice. Coordination Deadlock.
Methodology & More
DPBench adapts the classic Dining Philosophers puzzle into a reproducible benchmark that forces language-model agents to decide about shared resources either sequentially or simultaneously. Each agent can grab left or right forks, wait, or release; episodes end when a deadlock (everyone holding exactly one fork) occurs. The benchmark evaluates eight conditions (simultaneous vs sequential, three vs five agents, communication on/off) with metrics such as deadlock rate, throughput, and fairness.
Evaluations on GPT-5.2, Claude Opus 4.5, and Grok 4.1 show a stark asymmetry: sequential protocols produce near-zero deadlock, while simultaneous decisions produce high deadlock rates (up to 95–100% with 3 agents). Adding short, neighbor-to-neighbor messaging did not reliably fix the problem and sometimes increased deadlocks because messages arrived too late and agents often did not follow their stated plans (only 29–44% message-action consistency). Analysis attributes failures not to lack of problem understanding—the models can describe safe strategies—but to convergent reasoning: independent agents reason the same way and then act the same way, which in this task guarantees conflict.
Practical implication: systems that require concurrent decisions about shared resources should not rely on spontaneous coordination among identical LLM agents. Safer options include sequential turn-taking, explicit arbitration (locks or leader election), randomized tie-breakers, or training/fine-tuning agents with diverse policies. DPBench is released so teams can measure and track improvements in simultaneous coordination before deploying multi-agent systems in the wild. Planning Pattern.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
All authors have very low h-indices, no affiliations or top venue (arXiv) — limited credibility signal.