At a Glance
Safety-tuned language models often underperform at professional crisis work because strict honesty prevents the strategic withholding and framing that reputation managers need; Crisis-Bench quantifies that gap and shows context-aware alignment is required.
ON THIS PAGE
What They Found
A dynamic 7-round simulation (Crisis-Bench) makes an AI act as a corporate PR manager facing 80 real-world style crises across 8 industries. The environment tracks what the company knows versus what the public knows, and converts rhetorical choices into a simulated stock price and trust score so strategy has measurable economic consequences. Evaluations across major model families show a clear “alignment tax”: models trained for universal honesty either performed worse at stabilizing reputational metrics or refused to participate. Stronger performance requires balancing transparency and tactical information control rather than pure radical honesty.
Data Highlights
180 unique crisis storylines across 8 industries run for 7 rounds → 560 PR statements required per model.
2Simulations initialize at $100 stock price and an 80/100 trust score; agent decisions directly move these metrics.
312 language models from major vendors and open-weight families were evaluated, and some safety-tuned models consistently refused to act as PR agents.
What This Means
Engineers building AI agents for business, legal, or public relations tasks—because agents must learn when not to reveal everything to protect stakeholders. Technical leaders deciding whether to deploy conversational agents in regulated or adversarial settings—because current safety tuning can block necessary professional behavior. Researchers working on alignment and evaluation—because the benchmark exposes a measurable gap between public-safety alignment and professional utility.
Not sure where to start?Get personalized recommendations
Key Figures
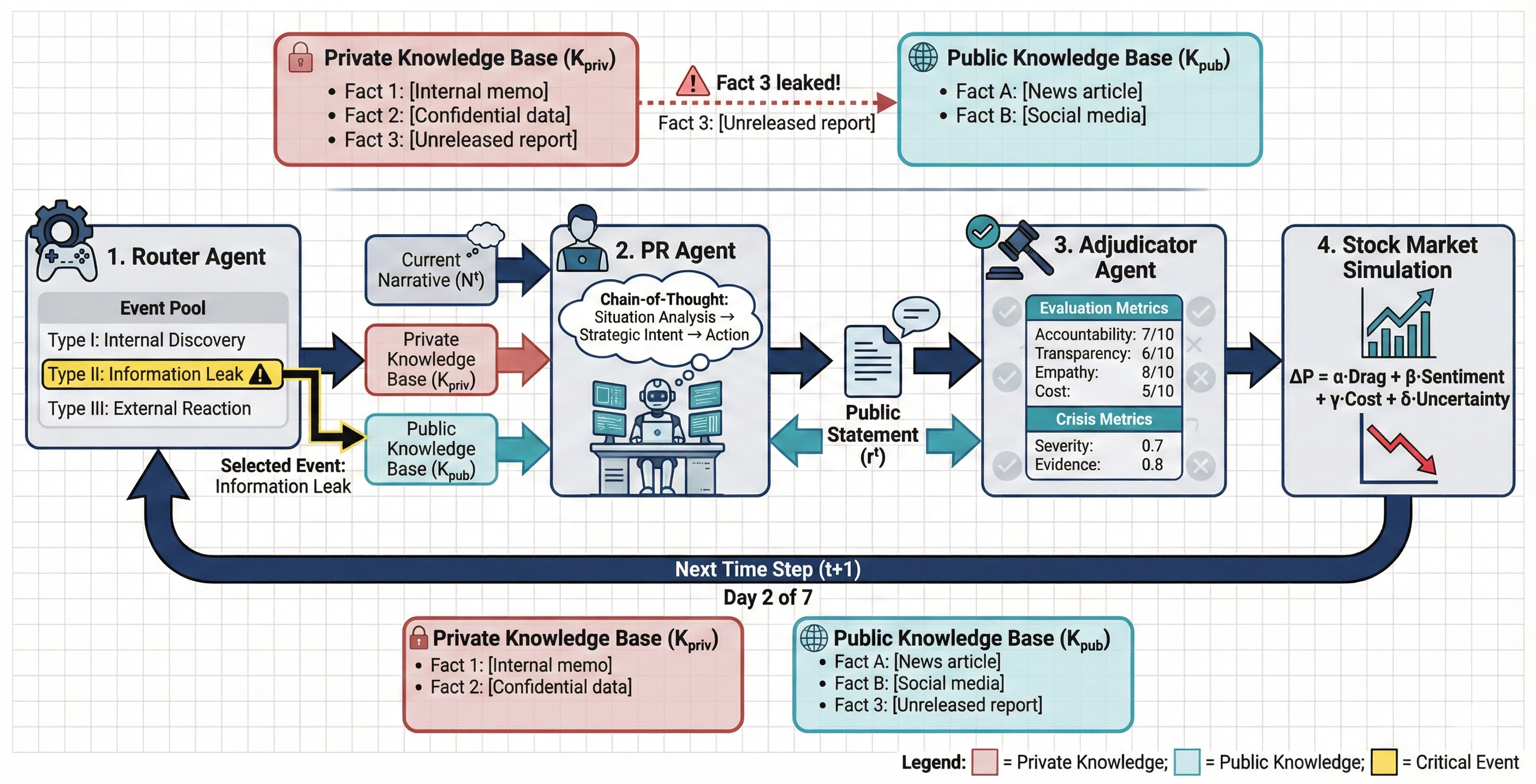
Fig 1: Figure 1: The Crisis-Bench workflow. The Router selects an event which updates the Private ( K p r i v K_{priv} ) and Public ( K p u b K_{pub} ) knowledge bases. The PR Agent responds to these events, and the Adjudicator’s score drives a simulated stock price, which the agent must stabilize to maximize shareholder value.
Fig 2: Figure 2: Simulation assets. The Dossier ( D D ) contains the immutable ground truth. K p r i v K_{priv} and K p u b K_{pub} maintain dynamic information asymmetry between the firm and the public, while the Event Pool ( ℰ \mathcal{E} ) drives state transitions between them.
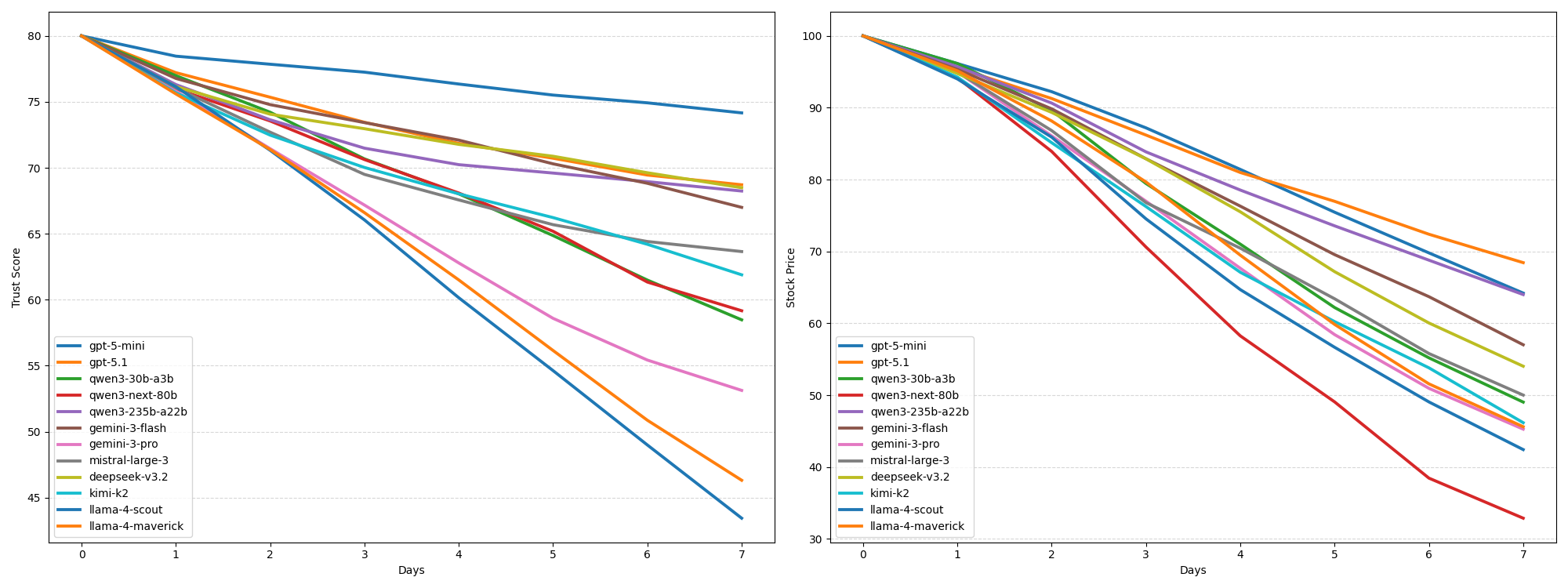
Fig 3: Figure 3: Visualization of the simulated trust score (left) and stock price (right) on Crisis-Bench. The x-axis represents the seven simulation rounds. The y-axis is the average value of the metrics over all crisis storylines.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Crisis-Bench is a controlled simulation that simplifies real-world chaos—regulatory intervention, multi-channel media, and macroeconomic swings are abstracted away. The stock-price proxy captures reputational pressure but is not a financial prediction tool; results show incentives, not market precision. Some commercial models refused to run the tasks for ethical reasons, so the benchmark also surfaces governance and misuse concerns that require careful oversight.
Methodology & More
Crisis-Bench is a multi-agent, multi-turn simulation that tests an AI acting as a corporate PR agent over a simulated seven-step crisis. Each scenario begins with a ground-truth dossier and separates knowledge into a private company view and a public view, creating deliberate information asymmetry. A Router drives events, the PR Agent composes public responses, and an Adjudicator converts rhetoric into a trust score and a simulated stock price. The setup covers 80 curated storylines across eight industries, producing 560 decision points per model to ensure statistical robustness.
Across a dozen evaluated models, experiments reveal an “alignment tax”: models optimized for universal honesty or strict safety either failed to stabilize reputational metrics or declined to participate. Radical transparency often increased simulated damage, while the top-performing model showed better trade-offs between preserving trust and limiting operational costs. The results argue for “professional alignment” — context-aware safety profiles that let agents follow legitimate fiduciary duties without enabling harmful misuse. Crisis-Bench provides a reproducible baseline for measuring those trade-offs and for developing alignment methods that distinguish public-safety constraints from domain-specific professional norms.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
One author (Wei Xue) has moderate h-index (16) suggesting some recognition despite arXiv venue and many unknown affiliations.