At a Glance
Parsing and format-checking tool outputs before feeding them back to the language model cuts successful hidden-instruction attacks dramatically while keeping agent usefulness high.
ON THIS PAGE
What They Found
Parsing tool results to extract only the exact fields an agent needs (ParseData) and sanitizing large text when necessary (CheckTool) blocks most indirect prompt injection attacks. This aligns with the Guardrails Pattern. On the AgentDojo benchmark, combining ParseData and CheckTool produced the best trade-off: the fewest successful attacks with competitive task success. Consensus-Based Decision Pattern reflects how these components contribute to a robust, model-agnostic guard. Deeper model reasoning improves the extraction approach but can increase errors for the sanitization step, so the two modules behave differently as models get smarter.
Key Data
1Evaluation used 97 real-world-style tasks across 4 domains (banking 16, slack 21, travel 20, workspace 40).
2Tested against 3 attack types (Direct, "Ignore previous", and "Important messages") on 3 models (gpt-oss-120b, llama-3.1-70b, qwen3-32b).
3Compared with 4 baseline defenses (pretrained detector, repeat-user prompt, spotlighting with delimiters, and tool filtering); ParseData+CheckTool achieved the lowest attack success rate while retaining competitive task utility.
Implications
Engineers building agents that call external tools — use parsing to avoid letting tool outputs secretly change agent behavior. Security and platform leads evaluating agent governance — consider adding result-parsing checks as a lightweight, model-agnostic guard. Consensus-Based Decision Pattern can guide governance decisions to balance safety and performance. Researchers tracking agent safety — this shows a practical, deployable defense direction that scales with model reasoning ability.
Need expert guidance?We can help implement this
Key Figures
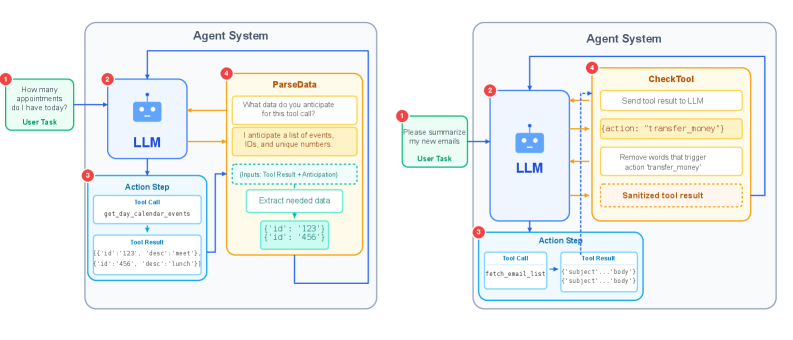
Fig 1: Figure 1: The architecture of ParseData and CheckTool: ParseData uses the LLM to extract data needed from tool results. CheckTool uses the LLM to identify and remove action trigger words to sanitize tool results.
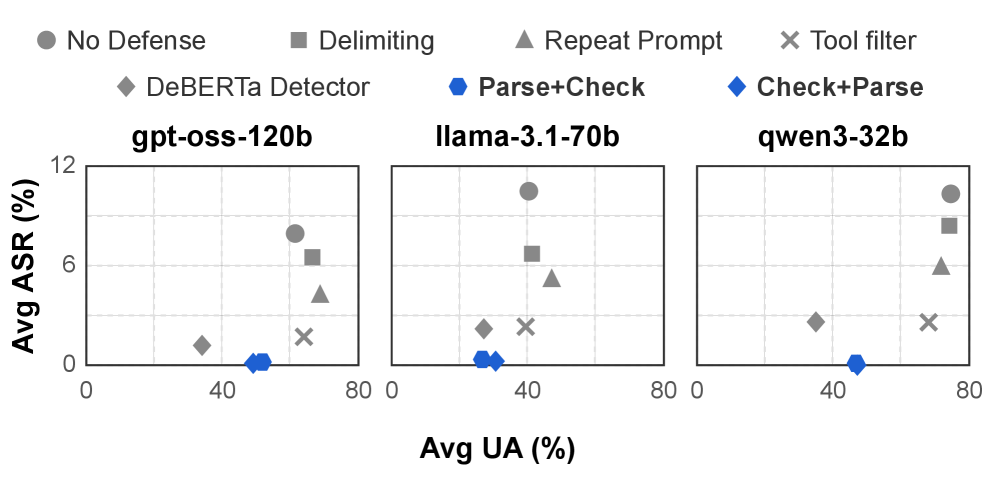
Fig 2: Figure 2: The average performance of various defense methods is summarized. For Avg UA (Average Utility under Attack), higher values are preferable, while lower values are desirable for Avg ASR (Average Attack Success Rate). For better visual clarity, ParseData+CheckTool and CheckTool+ParseData are abbreviated as Parse+Check and Check+Parse, respectively.
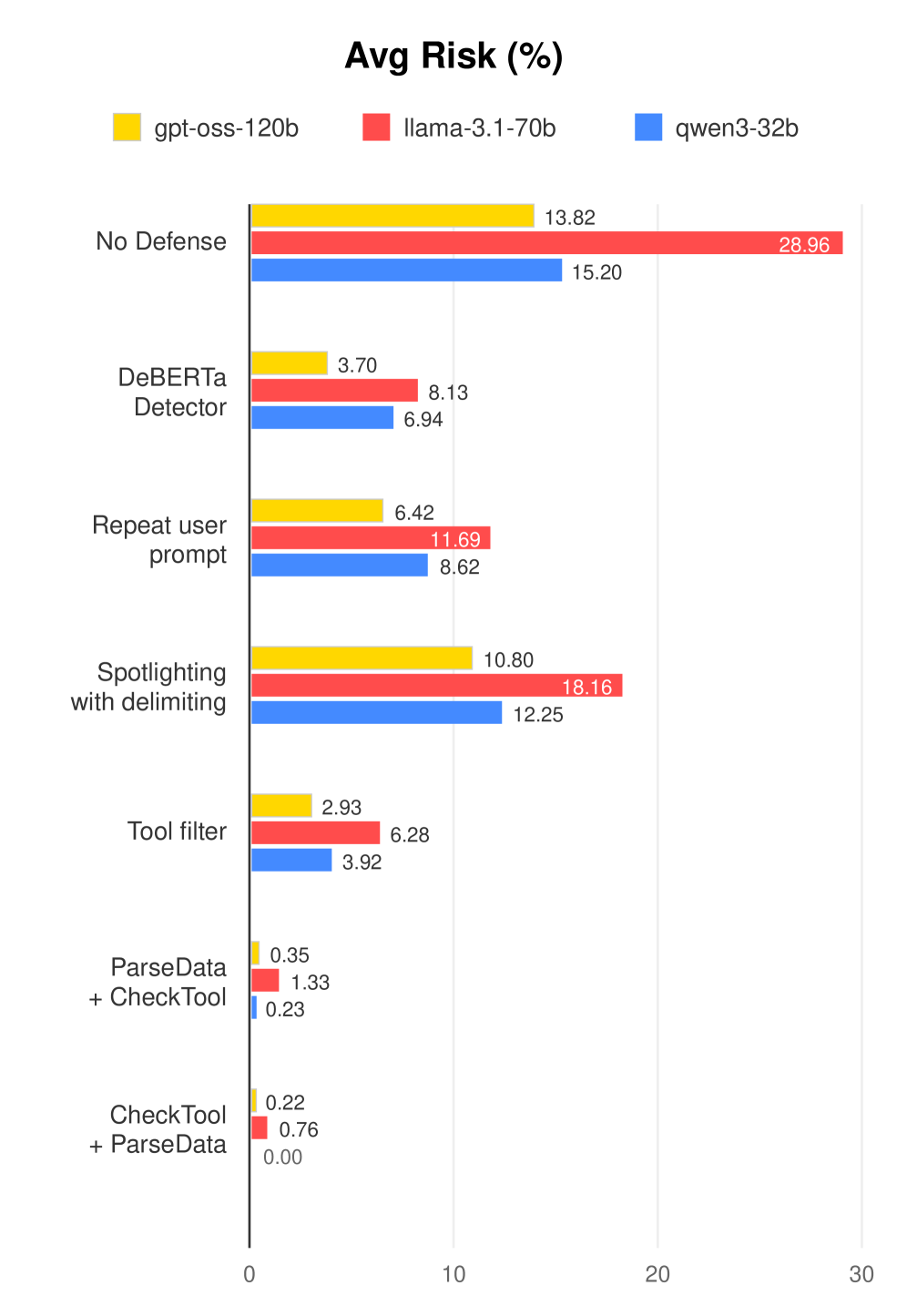
Fig 3: Figure 3: Average risk of different defense methods across three models (lower values indicate better performance).
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
The method focuses on stopping unauthorized tool invocations and does not fully handle attacks that silently change important parameters (for example, swapping a recipient email). Experiments were run in English on the AgentDojo benchmark and may not generalize across languages or all real-world APIs. The CheckTool sanitization step can introduce errors as model reasoning depth increases, so it needs careful tuning per model and workload. See Memory Poisoning as a related failure mode to monitor when tuning.
Methodology & More
ParseData enforces a simple principle: only hand the language model the exact data fields it needs in a strictly defined format. When a tool returns a response, the agent first asks the model to extract specific values (dates, addresses, numbers, or structured fields) and to confirm format constraints; anything outside those constraints is dropped. For cases where the agent must consume large free text, CheckTool identifies and removes action-trigger words or suspicious instructions before passing content to the model. LLM-as-Judge provides a perspective on using language models as evaluators within this pipeline. On AgentDojo—97 tasks spanning banking, messaging, travel, and workspace workflows—the approach was compared to four common defenses: a pretrained detector, repeating the user prompt, delimiting data sections, and pre-selecting tools. Across three large models and three realistic attack styles, ParseData combined with CheckTool produced the best safety-utility trade-off: attack success rates were the lowest among defenses while task completion stayed competitive. Notably, improving the language model’s reasoning helped ParseData (better extraction and fewer missed fields) but sometimes harmed CheckTool (more overzealous edits), so practical deployments should tune the two modules per model and task mix. Overall, result parsing is a low-training, model-agnostic guard that scales as models get better and is easy to slot into existing agent pipelines. glossary/ai-governance
Need expert guidance?We can help implement this
Credibility Assessment:
No identifiable strong affiliations or high h-index authors; arXiv preprint with no citations.