In Brief
Reusing cached model memory for judge agents often keeps overall accuracy but frequently makes the judge pick a different candidate; preserving cross-candidate interactions is essential to avoid silent decision shifts.
ON THIS PAGE
Key Findings
When a central judge recomposes cached pieces from multiple agent outputs instead of recomputing everything, the final task accuracy can stay about the same while the judge frequently selects a different candidate. This decision non-invariance happens across generation styles (sequential refinement and parallel exploration) and is worse when candidate order changes. Attention and masking analyses point to disrupted cross-candidate interactions—judges need fine-grained visibility across candidates, and simple reuse breaks that. consensus-based decision pattern.
Not sure where to start?Get personalized recommendations
Key Data
14 candidates per example were used (N=4) to isolate judge-side effects.
2A detector to flag safe vs. unsafe reuse instances scored an area under curve of ≈ 0.82.
3That detector achieved average precision ≈ 0.77 for predicting when reuse preserves judge selections.
Implications
Engineers building multi-agent systems and platform owners running agent orchestration should care because accuracy checks alone can miss silent changes in which candidate the system trusts. Researchers and evaluators using agent-to-agent evaluation should monitor selection consistency (not just final answers) and consider interaction-aware caching or gated recomputation for judges. Supervisor Pattern
Key Figures
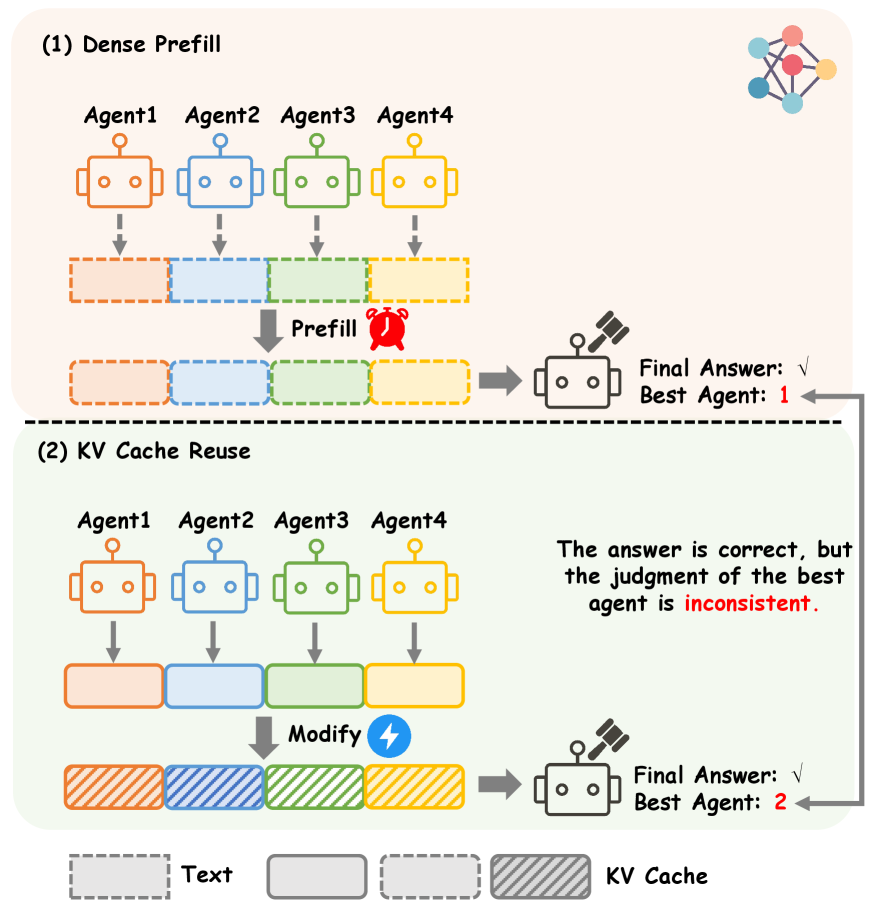
Fig 1: Figure 1: Illustration of decision non-invariance under judge-side KV cache reuse. Top : dense prefill recomputes the judge KV cache and selects Agent 1. Bottom : KV reuse stitches/modifies cached KV blocks, keeping the final answer correct but changing the selected best agent, despite identical candidate texts.
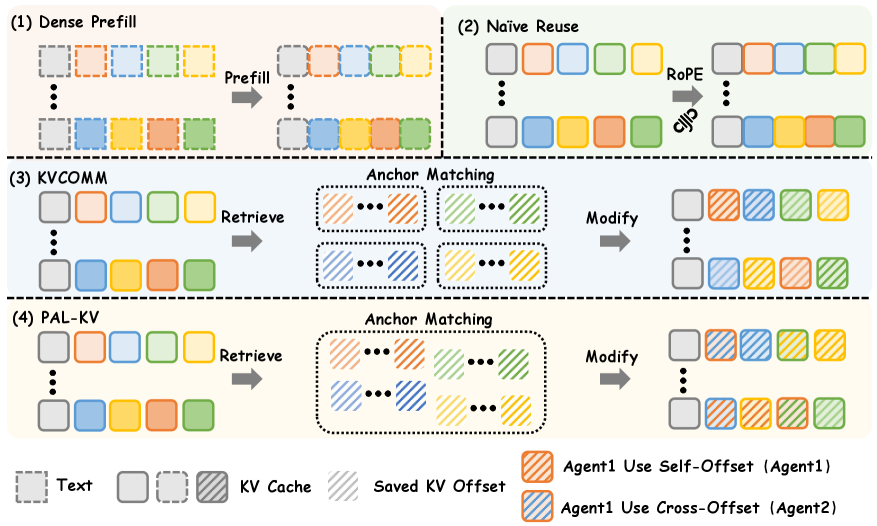
Fig 2: Figure 2: Judge-side KV cache construction for multi-candidate judging. Dense prefill recomputes the full judge cache, while Naïve Reuse aligns and stitches execution-side candidate KV chunks. KVCOMM retrieves anchor-based cache offsets to correct reused chunks, and PAL-KV pools anchors across agents for offset retrieval.
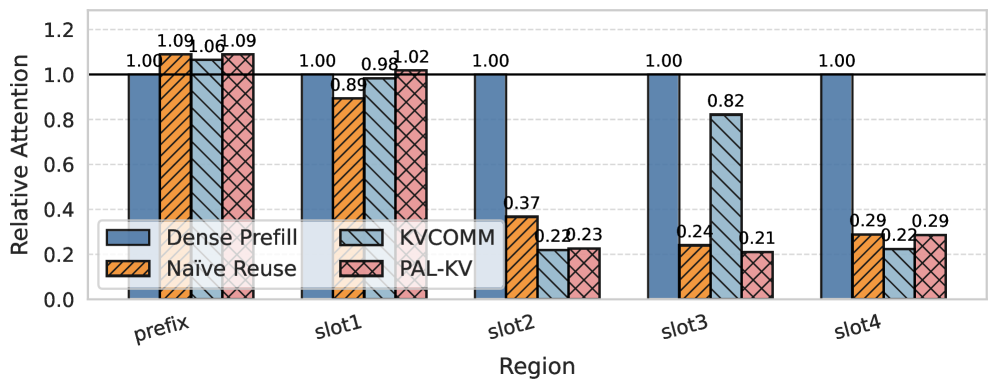
Fig 3: Figure 3: Relative attention mass over regions (prefix and candidate slots) under different KV reuse methods.
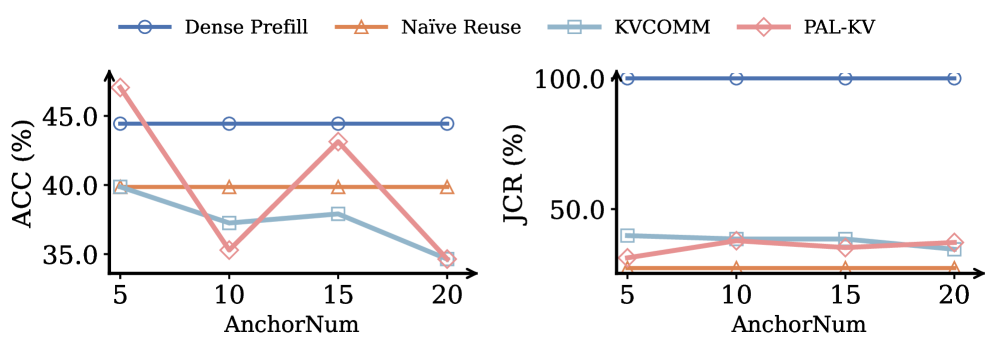
Fig 4: (a) Effect of anchor pool size.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
The study isolates judge-side effects by fixing candidate texts and disabling reuse on the generation side, so runtime trade-offs in full systems may differ. Results focus on the reuse methods tested and a set of benchmarks—other reuse schemes or model families might behave differently. Judge Consistency Rate (JCR) measures selection stability but does not itself indicate which selection is more correct or fair. Memory Poisoning
Methodology & More
The study examines what happens when a central judge in a multi-agent pipeline reuses cached model key–value (KV) blocks instead of computing a fresh encoding over the entire judge prompt. The setup fixes candidate texts (generated once) and compares dense recompute against several reuse strategies while testing two candidate-generation regimes: progressive refinement (sequential conditioning) and parallel exploration (independent candidates). To quantify whether reuse preserves selection behavior, the work introduces Judge Consistency Rate (JCR), the fraction of cases where the reused-cache judge picks the same candidate as dense recompute. Findings show that reuse often preserves the final task answer but can substantially change which candidate the judge picks—especially when candidate order is shuffled. Attention analyses and controlled ablations trace the problem to lost or diluted cross-candidate interactions when KV chunks are stitched or position-adjusted. Practical paths include selective retention of interaction-relevant tokens, small-to-large model cooperation to identify critical tokens, and risk-aware gating that recomputes the judge cache for high-risk instances. The authors also train a lightweight detector that predicts safe vs unsafe reuse with AUC ≈ 0.82 and AP ≈ 0.77, suggesting detection + selective recompute as a practical mitigation. Chain of Thought Pattern and LLM-as-Judge.
Test your agentsValidate against real scenarios
Credibility Assessment:
Authors have modest h-indices but no listed affiliations or venue prestige; limited signals of strong credibility.