At a Glance
A single AI given a small, well-designed set of actionable skills can match many cooperating agents while using far fewer tokens and answering about twice as fast; however, accuracy collapses once the skill library grows past a capacity threshold driven by overlapping skill meanings.
ON THIS PAGE
Core Insights
Equipping one AI model with a compact library of skills reproduces the benefits of multi-agent setups while cutting communication cost and speeding up answers. When the skill list is small (a few skills), performance and final outputs match multi-agent systems; token use drops by roughly half and response speed improves substantially. As the number of skills grows, the model’s ability to pick the right skill breaks down non-linearly — not gradually — and the main driver is semantic similarity between skills, not just sheer count. Organizing skills in a simple hierarchy (coarse-to-fine routing) recovers much of the lost accuracy when flat selection fails. Tree of Thoughts Pattern
Data Highlights
1Skill-based single-agent setups matched multi-agent accuracy while using ~54% fewer input/output tokens on benchmark tasks.
2Average answer speed improved by about 50% compared with multi-agent coordination in the experiments.
3With large skill libraries (≥60 skills), flat selection fell to ~45–63% accuracy, while hierarchical routing maintained ~72–85% accuracy. (Model fit for the scaling law achieved R² > 0.97.)
What This Means
Engineers designing agent architectures who want lower cost and faster responses should consider replacing small multi-agent setups with a single AI plus skills. Technical leaders evaluating trade-offs between speed/cost and reliability can use the skill-capacity threshold to decide when to keep skills compact or add hierarchical routing. Researchers studying action selection or agent modularity will find the semantic confusability angle useful for follow-up work. LLM-as-Judge
Test your agentsValidate against real scenarios
Key Figures
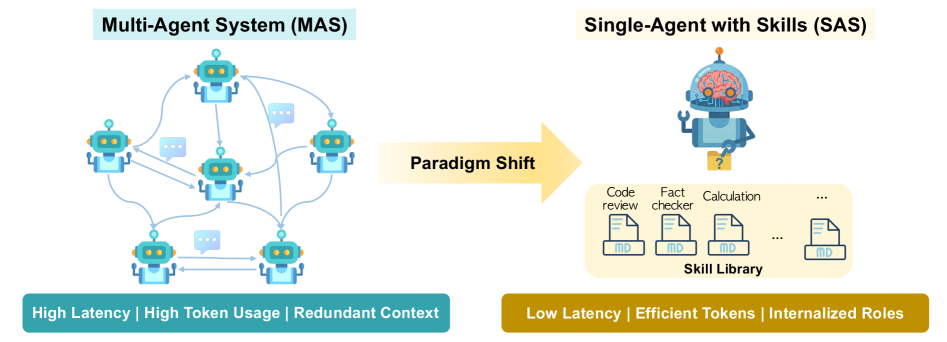
Fig 1: (a) From multi-agent systems to a single agent with skills.
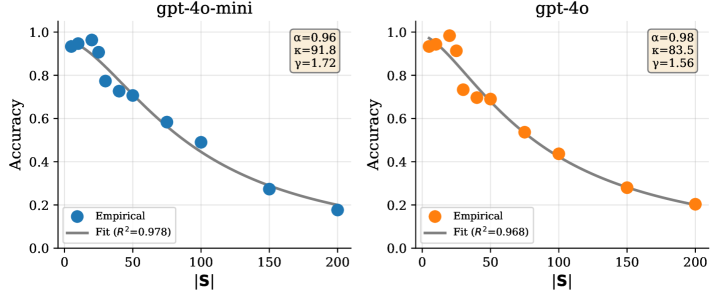
Fig 2: Figure 2 : Scaling law fit quality. The proposed functional form Acc ≈ α / ( 1 + ( | 𝐒 | / κ ) γ ) \textsc{Acc}\approx\alpha/(1+(|\mathbf{S}|/\kappa)^{\gamma}) achieves excellent fit ( R 2 > 0.97 R^{2}>0.97 ) for both models, validating the theoretical model.
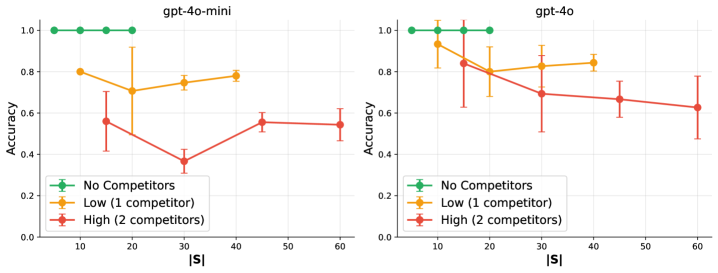
Fig 3: Figure 3 : Effect of skill competitors on selection accuracy. Green: no competitors (each skill unique). Orange: 1 competitor per skill. Red: 2 competitors per skill. At fixed total library size, higher confusability leads to lower accuracy, demonstrating that semantic similarity—not library size alone—drives selection errors.
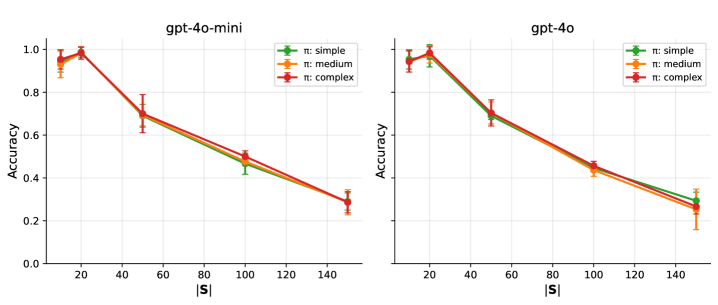
Fig 4: Figure 4 : Effect of execution policy complexity on selection accuracy. Each panel shows results for one model. Contrary to expectations, the three complexity levels show largely overlapping performance curves.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Experiments used synthetic, controlled skill libraries rather than naturally occurring skill sets, so real-world behavior may differ. Results focus on systems that can be compiled (no private hidden state or required parallel sampling), so not all multi-agent designs are eligible for replacement. The study measured skill-selection accuracy and intermediate costs; it did not fully quantify how selection mistakes propagate to final task outcomes in every application domain. Context Drift
Deep Dive
Converting a cooperative multi-agent setup into one AI that selects from a library of internalized skills can preserve functionality while cutting the back-and-forth communication that makes multi-agent systems costly. The study formalizes when such a compilation is possible (agents must have serializable communication, shared history, and homogeneous backbone) and then runs controlled experiments: synthetic skill libraries with 5–200 distinct skills across eight domains were created so selection behavior could be measured precisely.
When libraries are small (typical compiled systems in the experiments used 3–4 skills), one AI with skills matched multi-agent accuracy while using about 54% fewer tokens and answering about 50% faster. As the library grows, selection accuracy follows a non-linear phase transition: accuracy stays high up to a critical capacity, then drops sharply. Experiments show that overlap in what skills mean (semantic confusability) explains much of the drop, not library size alone. A simple fix—hierarchical routing that picks a coarse domain before a fine-grained skill—restores much of the lost accuracy in large libraries, matching cognitive ideas like chunking. Practical takeaway: prefer compact, well-separated skills or add hierarchy when scaling; test for semantic overlap before expanding a skill set. Chain of Thought Pattern Semantic Capability Matching Pattern
Not sure where to start?Get personalized recommendations
Credibility Assessment:
Single author with very low h-index, arXiv preprint; limited reputational evidence despite one citation.