Key Takeaway
Training orchestration to explicitly penalize slow execution paths shortens the end-to-end wait time when many AI agents run in parallel, while keeping task accuracy largely intact.
ON THIS PAGE
Key Findings
Allowing groups of agent tasks to run in parallel and removing needless dependencies lets multiple agents actually execute at the same time. When the training objective includes a penalty for long execution paths, the learned orchestrations pick layouts that shorten the slowest chain of operations (the critical path). Doing so reduces wall-clock latency across coding and math benchmarks without causing major drops in functional performance. Tree of Thoughts Pattern
Not sure where to start?Get personalized recommendations
Data Highlights
1Latency-aware training consistently reduced the length of the critical execution path relative to training on accuracy and cost alone across the evaluated benchmarks (HumanEval, GSM8K, MATH).
2Layer-wise parallel execution was enabled by removing intra-layer dependencies, allowing operators within a layer to run concurrently instead of sequentially.
3Optimizing for latency explicitly (via a latency penalty) produced trade-off points with similar accuracy but noticeably lower end-to-end response time compared to accuracy-only objectives on HumanEval and math benchmarks.
What This Means
Engineers building interactive assistants or real-time decision systems where response time matters will benefit—this approach reduces wait time when many specialized agents collaborate. Technical leaders evaluating multi-agent orchestration should consider adding latency into their optimization goals to meet user-facing speed requirements without reengineering operator internals. Semantic Capability Matching Pattern
Key Figures
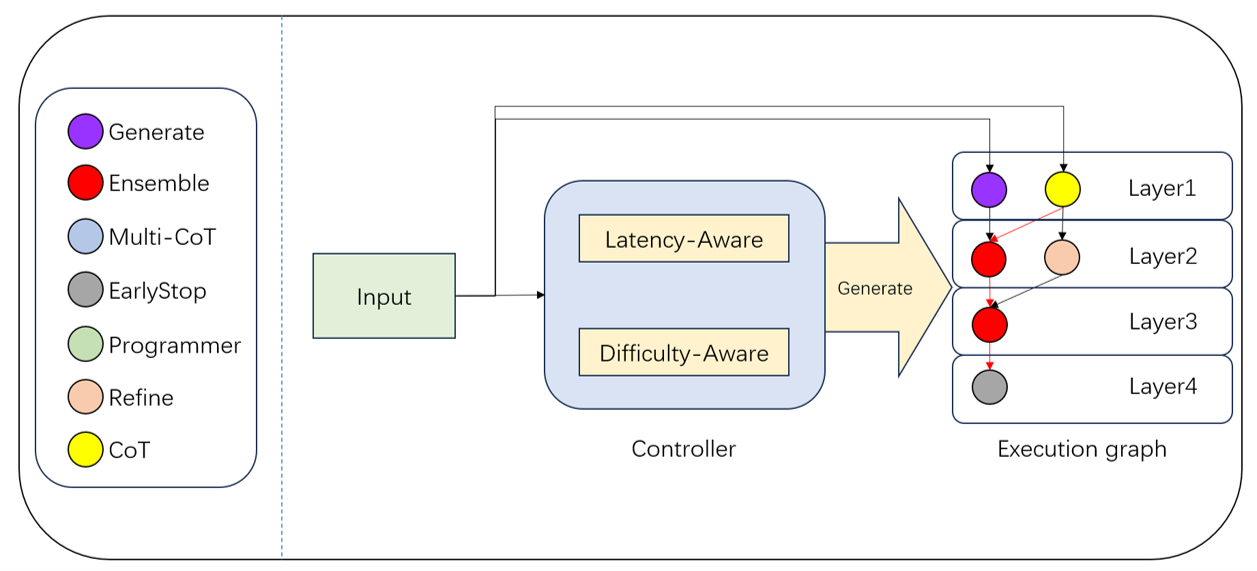
Fig 1: Figure 1: (Left): Building blocks for LAMaS; (Right): Workflow illustration of LAMaS. The orchestrator generates a layer-wise execution graph, where operators within the same layer execute in parallel. Red arrows indicate the critical execution path.
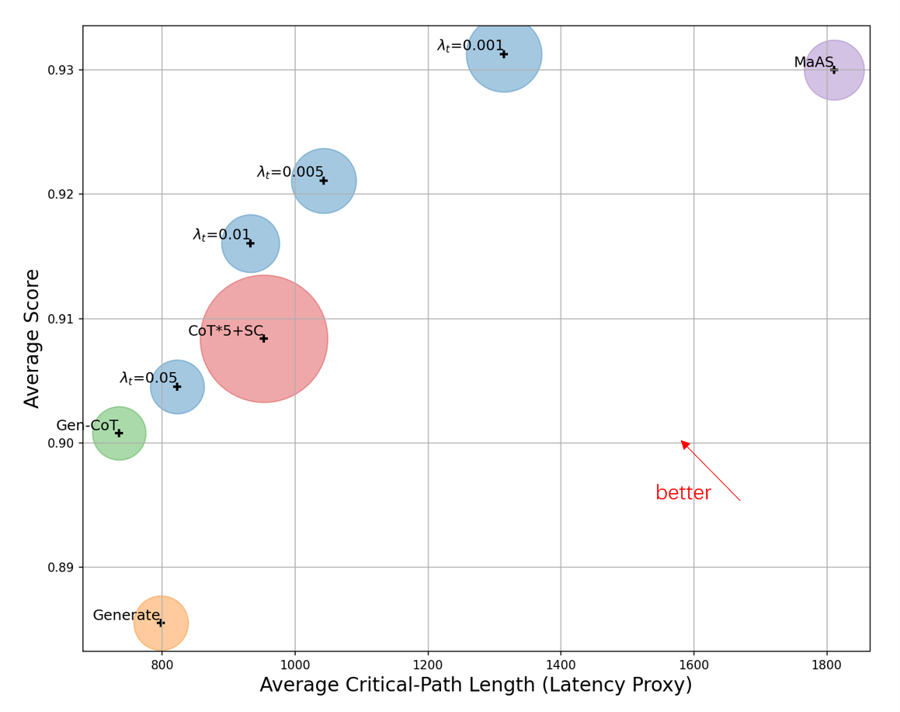
Fig 2: Figure 2: Accuracy–latency trade-off on HumanEval. Marker size indicates average cost. Blue points correspond to LAMaS under different latency penalty coefficient λ t \lambda_{t}
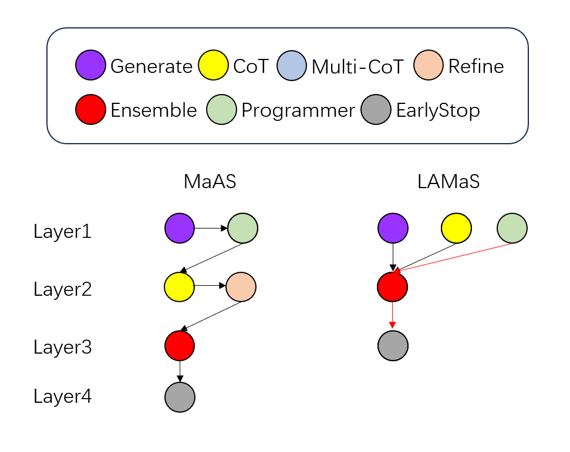
Fig 3: Figure 3: Case study. Red arrows highlight the critical execution path, formed by the slowest operator at each layer.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Measured improvements reflect algorithmic orchestration choices, not system-level deployments—real-world latency also depends on hardware, network, and runtime integration. Experiments used code and math benchmarks (HumanEval, GSM8K, MATH), so results may differ for dialogue-heavy, vision, or tool-heavy workflows. Operator definitions were left unchanged, so additional gains may be possible with system engineering or operator re-design. Guardrails Pattern
Full Analysis
Orchestration for many collaborating AI agents often assumes sequential interactions, which hides opportunities for parallel work and creates long wait times when many steps accumulate. By organizing operators into layers and removing unnecessary dependencies inside a layer, operators can run concurrently. Under that layer-wise parallel setting, the end-to-end latency is dominated by the slowest operator chosen in each layer—the "critical execution path." Training an orchestrator without considering latency tends to ignore these parallel execution effects and can produce orchestrations that look efficient in cost or accuracy but still wait too long in practice.
Introducing a latency-aware term into the training objective guides the orchestrator to prefer execution graphs that shorten the critical path while preserving task performance. The approach keeps operator behavior fixed (no changes to how individual agents work) and focuses on which operators to pick and how to layer them. Across code generation and math benchmarks, learned orchestrations that include a latency penalty reduce critical-path length and cut end-to-end waiting time compared to accuracy-only training, showing a practical way to make multi-agent systems more responsive for time-sensitive applications. For production use, algorithmic gains should be combined with system-level tuning (parallel runtimes, resource placement) to capture full real-world benefits. Chain of Thought Pattern Supervisor Pattern
Explore evaluation patternsSee how to apply these findings
Credibility Assessment:
One author with modest h-index (~6) but otherwise no strong affiliations or top venue; limited evidence of established credibility.