Key Takeaway
Turning agent and tool calls into lightweight "futures" plus a two-level control plane cuts long tail waits and lets teams run complex multi-step AI workflows without changing their Python code.
ON THIS PAGE
Key Findings
Replacing direct agent and tool calls with automatically generated stubs that return futures gives the runtime visibility into dynamic workflows without forcing new programming models. A global controller periodically computes policies Consensus-Based Decision Pattern while local controllers enforce them immediately, enabling runtime migration, routing, and prioritization of work. With a managed state layer that separates logical state from physical placement, the system can move sessions safely to reduce head-of-line blocking and use resources more efficiently Tree of Thoughts Pattern.
Data Highlights
134–74% reduction in P95–P99 tail latency in stateful workloads compared to baselines
2Sustains under 50s average latency at 80 requests per second while competing frameworks fail under load imbalance
3Up to 2.9× end-to-end speedups on recursive software-engineering workflows; baselines showed >2.1× worse load imbalance in some tests
What This Means
Engineers building multi-step AI workflows and platform teams who need predictable performance and efficient resource use will benefit. Technical leads can use the futures+control approach to reduce tail latency and implement new scheduling policies quickly, without forcing developers to rewrite code Supervisor Pattern.
Not sure where to start?Get personalized recommendations
Key Figures
![Figure 1 : An example agentic application: Exemplifying a software engineering company setup based on a MetaGPT [ 21 ] workflow for software development.](https://arxiv.org/html/2601.05109v1/x1.png)
Fig 1: Figure 1 : An example agentic application: Exemplifying a software engineering company setup based on a MetaGPT [ 21 ] workflow for software development.

Fig 2: Figure 2 : Nalar Overview: Nalar takes user-specified files and generates stubs (§ 3.1 ) that replace original function calls with controllable hooks to generate futures (§ 3.2 ). These stubs act as a conduit between the user program and the framework’s controllers. At deployment, Nalar launches and manages the runtime (§ 4 ), where component-level controllers and the global controller coordinate to enforce scheduling, routing, and resource policies.
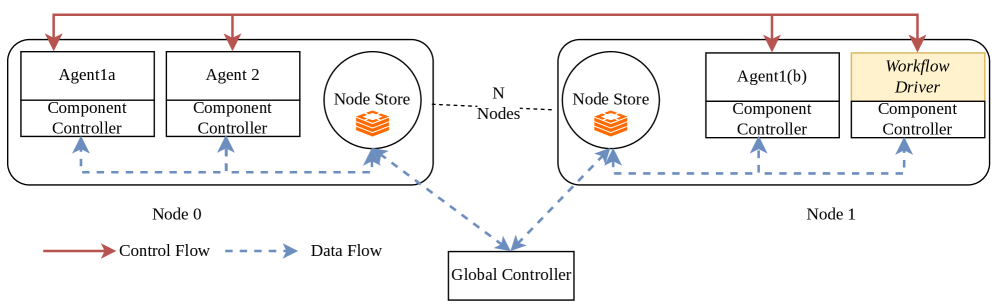
Fig 5: Figure 5 : Nalar ’s architecture: The figure shows Nalar ’s two-level control. Each component has an associated controller with it. Each node has a local node store. The global controller communicates with each agent and workflow driver, through the node store.
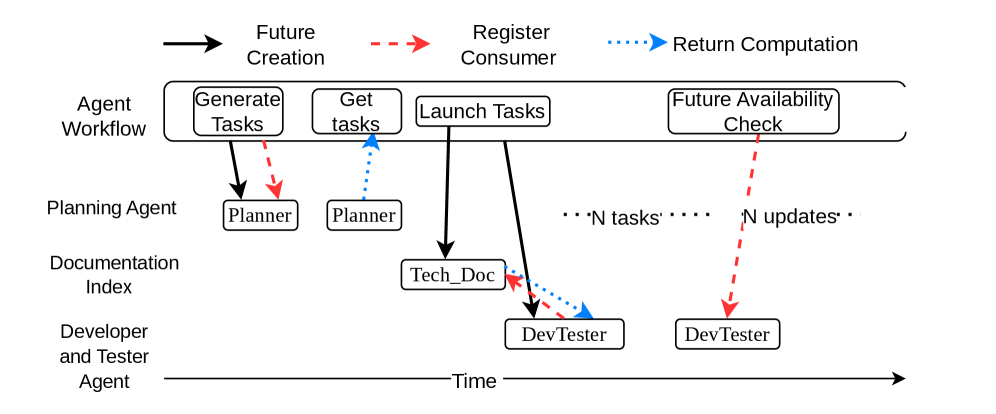
Fig 7: Figure 7 : Future Generation Timeline: For the agent workflow depicted in Figure 4 we depict a timeline for future generation and how their consumers are updated and their values realized in Nalar
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Nalar does not provide automatic fault recovery; failures are surfaced to the driver for retry logic. Managed state implies constraints: session-migratable state is supported, but batching cannot be used alongside per-session managed state. Evaluation used specific hardware and LLM backends, so exact gains may vary on different infra or model stacks. This aligns with potential failure modes like Memory Poisoning.
Full Analysis
Nalar instruments ordinary Python agent and tool calls by auto-generating lightweight stubs that return futures—objects that carry metadata about dependencies, session identity, and execution context. Those futures let the runtime observe the dynamic computation graph of multi-agent workflows without forcing developers to adopt new abstractions. A managed state layer decouples logical session data from where code runs, enabling safe session migration when it helps performance. Operational control is split into two levels: a global controller that periodically aggregates telemetry and computes high-level policies, and component-level controllers that enforce those policies immediately as futures are created or completed. A node-local store brokers decisions between the two levels to avoid a centralized bottleneck. In practice, this lets the system migrate work to avoid head-of-line blocking, rebalance capacity across branches during skewed load, and prioritize high-value sessions. In their evaluation, Nalar reduced tail latency substantially, sustained higher throughput under imbalance, and delivered up to 2.9× speedups on a realistic software-engineering workflow. The design trade-offs include explicit constraints around batching and no built-in fault recovery, but the approach provides a practical path to running reliable, stateful multi-step AI workflows in production. This separation mirrors the Tree of Thoughts Pattern in structuring solution steps.
Explore evaluation patternsSee how to apply these findings
Credibility Assessment:
Includes established researchers (e.g., Jayanth Srinivasa h~13) and multiple moderate h-index authors; arXiv but author reputations add credibility.