The Big Picture
A central planner that picks and guides existing agents over a constrained workflow makes automated feature engineering far more reliable—raising success from 0.600 or 0.333 to 0.833 pass@3 on a realistic PySpark benchmark.
ON THIS PAGE
Key Findings
Coordinating off-the-shelf agents with a planner that knows the workflow graph and past failures produces much more reliable, production-ready feature code than fixed or random agent orderings. The planner selects which actor to call next, crafts context-aware prompts, retries failed steps (up to five times), and uses downstream errors to correct upstream outputs. The system integrates human checks when needed and stitches generated code, tests, and configs into the repo via pull requests. On a 10-task PySpark benchmark, planner-guided runs succeeded far more often than baselines consensus-based decision pattern.
Data Highlights
1Planner-guided framework mean pass@3 = 0.833, versus 0.600 for a fixed sequential workflow and 0.333 for random actor selection.
2Planner-guided approach gives about a 39% relative improvement over the fixed workflow (0.833 vs 0.600) and roughly 150% relative improvement over random selection (0.833 vs 0.333).
3Benchmark used 10 realistic PySpark feature-engineering tasks (plus one held-out dev task); actors could retry failed steps up to K=5 times during execution.
What This Means
ML engineering teams building or automating feature pipelines should care because the planner approach reduces broken runs and produces repo-ready code, tests, and configs with fewer manual fixes. Technical leaders evaluating automation tooling can use this as evidence that smart orchestration—rather than more or larger models—improves reliability in multi-step engineering workflows. See how Coding Assistants are shaping practice.
Avoid common pitfallsLearn what failures to watch for
Key Figures
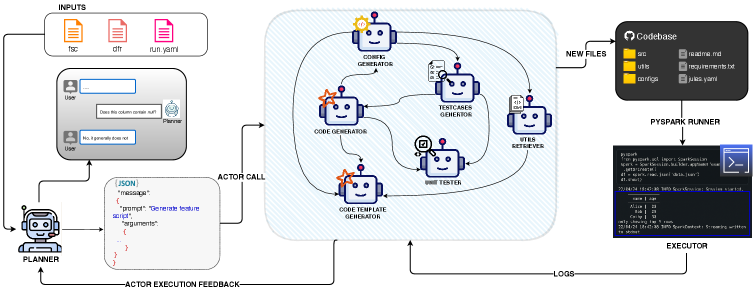
Fig 1: Figure 1: Overview of our approach, illustrating interactions between the planner, actors, and executor. Actors and their dependencies match the actual the development environment E E used in experiments.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
The benchmark is small (10 tasks) and focused on PySpark feature engineering, so results may not hold for every codebase or language. Experiments used fixed prompting and a single large language model; different prompt designs or models could change outcomes. Human-in-the-loop behavior was modeled but during benchmarking human help was set to ‘unavailable,’ so real-world gains when humans participate may differ (for better or worse). For real-world robustness considerations, reflect on Context Drift.
Deep Dive
The system treats a project as a constrained graph where each node is an actor (a tool or agent that performs a subtask) and edges define allowed next steps. A language-model-powered planner tracks short-term memory of past inputs, outputs, errors, and fixes; it chooses the next actor, composes context-aware prompts, decides when to ask for human confirmation, and integrates results into the repository. Actors expose loose success checks and can retry up to five times; when they fail they must explain the failure and propose a fix, allowing the planner to reason about upstream vs downstream causes and apply targeted corrections. Evaluation used a novel, production-like PySpark benchmark of 10 feature-engineering tasks that require scripts, unit tests, and configuration files. Compared to two baselines—a fixed sequential actor order and a graph-constrained random actor chooser—the planner-guided approach achieved mean pass@3 of 0.833 versus 0.600 and 0.333, respectively. That jump shows that dynamic, topology-aware orchestration and feedback-driven retries substantially improve end-to-end reliability. Limitations include a small dataset, reliance on downstream validation and fixed prompting, and the use of a single large model during testing. Future work suggested by the authors includes fine-tuning the planner, adding longer-term memory, expanding the benchmark, and exploring richer multi-agent collaborations to increase robustness and generality. Chain of Thought Pattern Tree of Thoughts Pattern
Need expert guidance?We can help implement this
Credibility Assessment:
All authors show low h-indexes and no notable institutional or venue signals.