The Big Picture
Per-step, experience-driven model selection can dramatically lower cost and speed up multi-agent workflows while preserving or improving task success.
ON THIS PAGE
Key Findings
Routing the best model for each subtask using a growing database of past executions lets systems escape the usual trade-off between performance, cost, and speed. EvoRoute stores step-level records, finds similar past subtasks, filters candidates by a cost/quality/time trade-off, and then picks the best model for the moment. It explores different model choices proactively to build this experience, then uses that history to run fast, cheap, single-shot executions in production. Pareto-optimal set
Avoid common pitfallsLearn what failures to watch for
Data Highlights
1Up to 10.3% improvement in task success compared to vanilla agent systems.
2Runs at roughly 20% of prior monetary cost (about an 80% cost reduction).
3Execution is nearly 3× faster (latency reductions reported over 70%).
What This Means
Engineers building multi-agent AI systems who need to cut cloud bills and speed up end-to-end workflows without sacrificing accuracy. agent track record Platform owners and technical leads deciding which models to deploy can use the approach to build an "agent track record" and stronger multi-agent trust signals. Researchers can adopt the step-level logging pattern to evaluate and compare agent reliability across roles Chain of Thought Pattern.
Key Figures

Fig 1: Figure 1: The agent system trilemma. Existing (deep research) agentic systems excel in certain aspects, yet none of which can fulfill the three characteristics spontaneously.

Fig 2: Figure 2: The overview of our proposed EvoRoute .

Fig 3: Figure 3: Comparative analysis across three key metrics: performance, cost, and delay, on all subsets of GAIA. All metrics are globally normalized, and values for cost/delay are inverted, such that a larger enclosed area signifies better economy/efficiency.
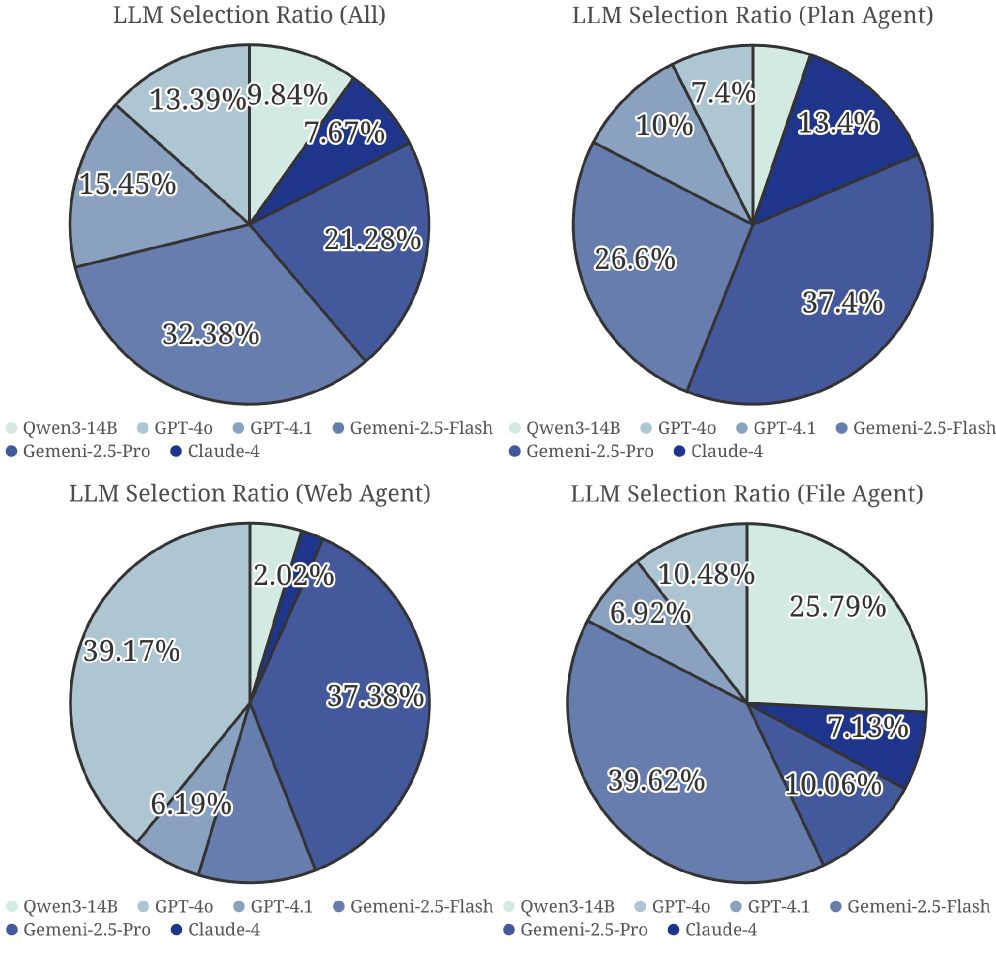
Fig 4: Figure 4: LLM selection distribution of EvoRoute +CK-Pro across different agent roles.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Results are measured on a limited set of agent frameworks (CK-Pro and Smolagents) and standard benchmarks, so performance may vary on other architectures like OWL or Agent-Orchestra. The system requires an initial exploration phase that incurs extra invocation cost to populate its experience base. Routing depends on finding similar past subtasks—very novel or out-of-distribution tasks may be harder to route optimally.
Deep Dive
EvoRoute treats multi-step agent workflows as a sequence of subtasks and records detailed, step-level execution traces into an experience base: the role, the exact subtask text, which model was used, tools invoked, cost, duration, and whether the step succeeded. For each new subtask it retrieves semantically similar past records, filters candidate models to a Pareto-optimal set (not dominated across cost, speed, and success), and uses a lightweight decision model to choose which model to run at that step. The method runs in two phases. During optimization it explores multiple model choices in a tree-like fashion to build diverse experience. During inference it uses the accumulated experience to follow a single, low-cost, fast path. Empirical tests on GAIA, BrowseComp+, and other benchmarks show up to 10.3% higher task success while cutting costs by about 80% and speeding up execution roughly 3×. The approach is practical for teams wanting to reduce operational expense and improve responsiveness: it creates a usable "agent track record" for model selection, but requires upfront exploration and may need careful coverage to handle rare or novel subtasks.
Need expert guidance?We can help implement this
Credibility Assessment:
Several authors have moderate h-index (up to ~18) indicating some established researchers, though venue is arXiv.