At a Glance
A tiny, fully local rule — create a new token when a node hasn't been visited for a preset time — stops a stealthy attacker from permanently killing decentralized learning, while keeping message traffic bounded and preserving convergence with a small, quantifiable bias.
ON THIS PAGE
Key Findings
Letting each node recreate a random-walk token if it hasn't seen one for a set interval prevents the network from ever permanently losing all tokens, even when some nodes probabilistically terminate tokens. The mechanism keeps the number of active tokens bounded (so the network isn't flooded) and lets decentralized stochastic gradient descent decentralized stochastic gradient descent still converge, though the optimizer can be shifted slightly by the attacker. Experiments show the method recovers after total wipeouts and still works with multiple malicious nodes (demonstrated up to 10% of nodes in a 100-node test).
Data Highlights
1Permanent extinction probability = 0: the token population is guaranteed to be recreated (no permanent halt) under the proposed rule (almost sure non-extinction).
2Empirical recovery observed with up to 10% of nodes acting maliciously in a 100-node network — token population rebounds after being driven to zero.
3Expected peak number of tokens can be controlled so it does not grow with network size (theoretical regime makes peak population independent of N).
Implications
Engineers building decentralized learning systems or message-passing algorithms: implement local recreate-if-not-seen logic to stop stealthy node-level sabotage without central control. Technical leads and security teams evaluating agent reliability: this gives a low-cost way to make token-based coordination robust against malicious or flaky participants.
Explore evaluation patternsSee how to apply these findings
Key Figures
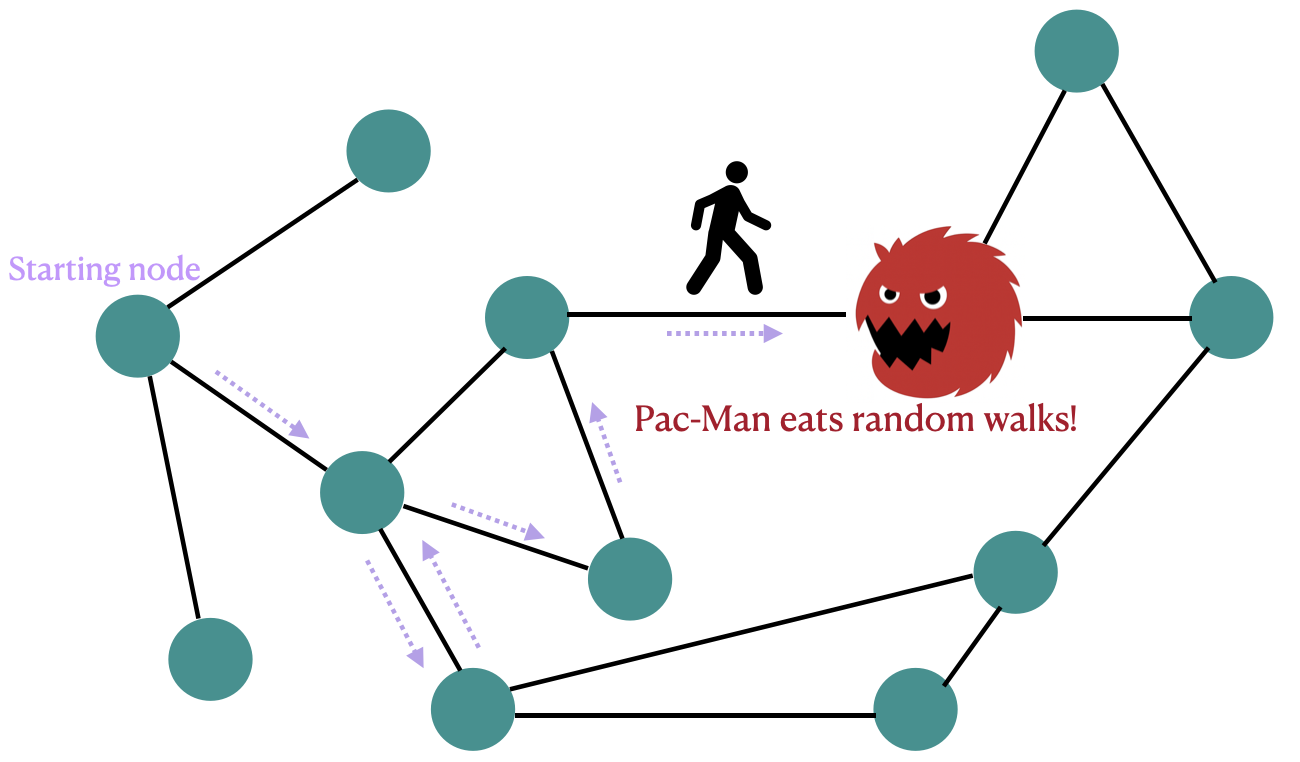
Fig 1: Figure 1 : An illustration of the Pac-Man attack: A malicious node (shown in red) intercepts and “eats” (terminates) any visiting RW with a positive probability. Despite behaving like a benign node to its neighbors, it prevents the random walk from continuing, leading to eventual extinction of all walks in the network.
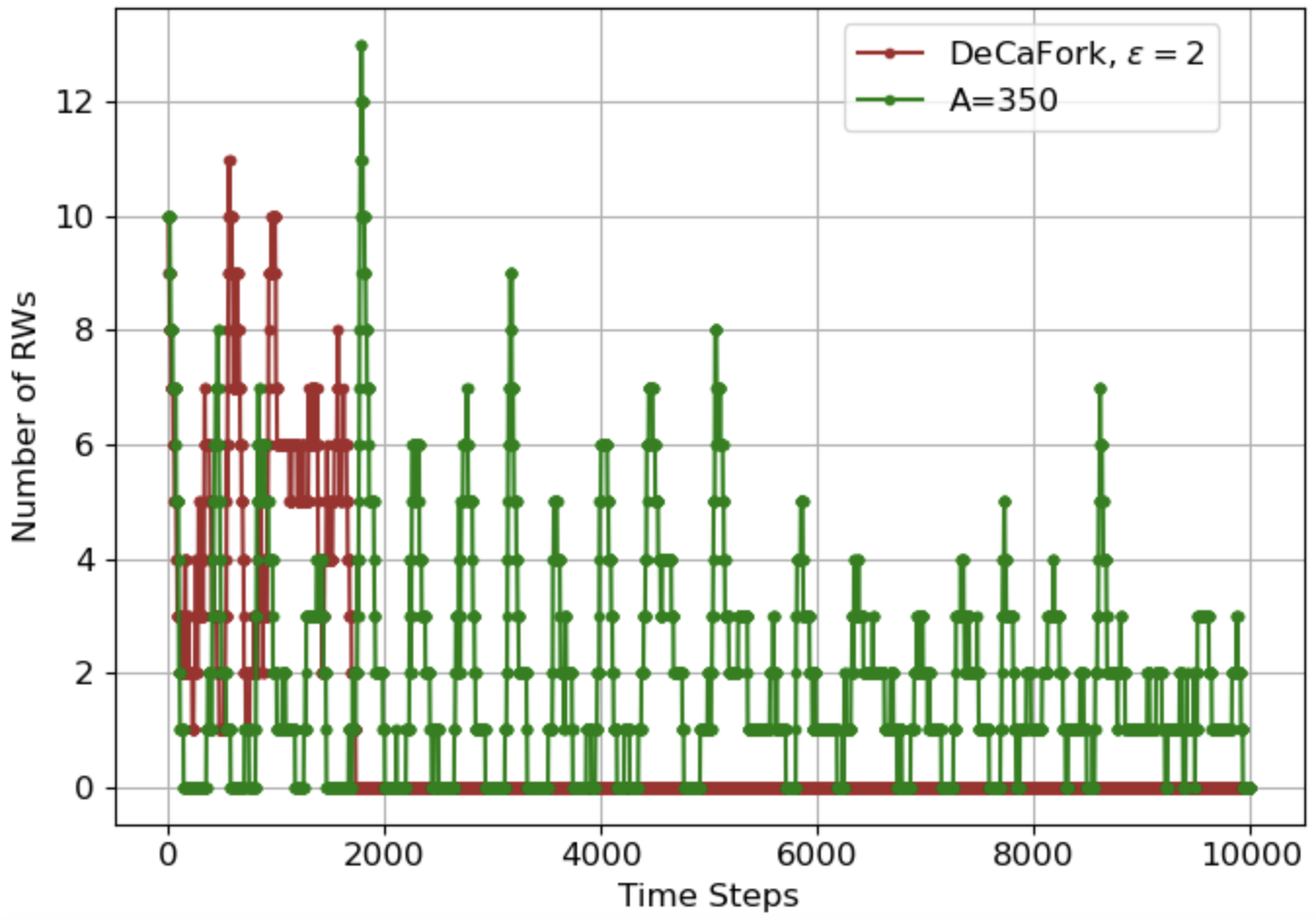
Fig 2: (a) CIL and DecAFork
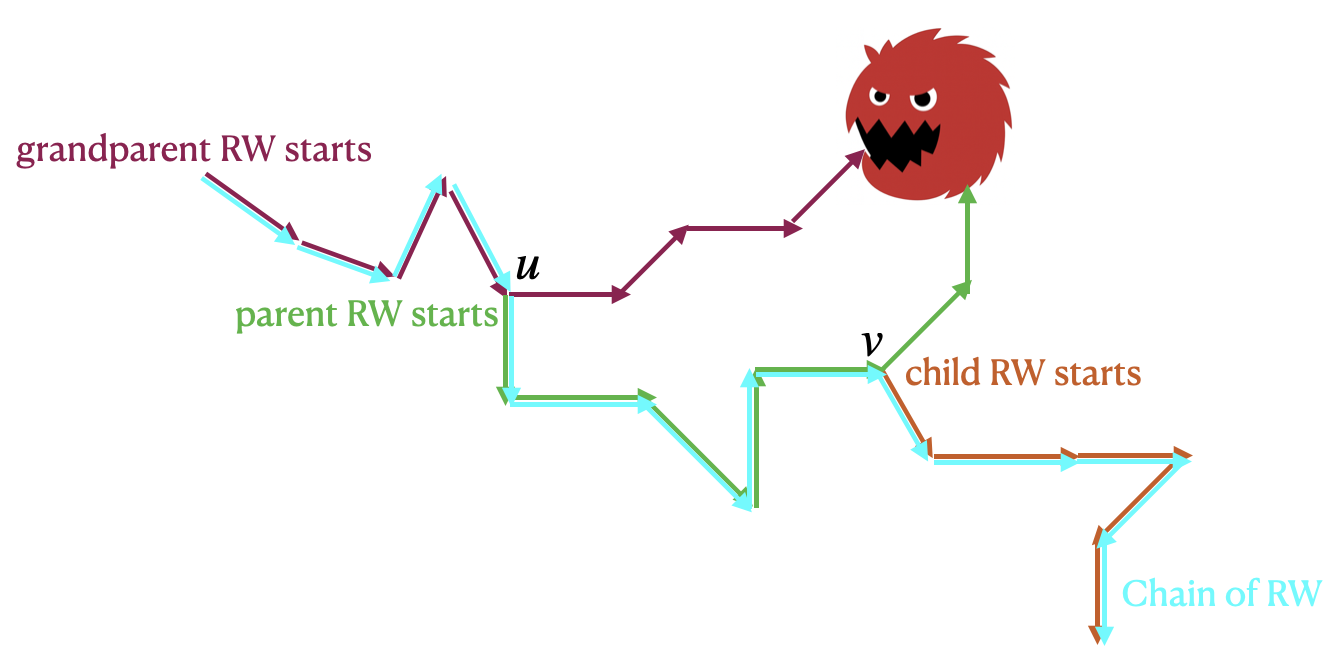
Fig 3: Figure 3 : An example of a chain of RWs. When a benign node u u has not been visited for A u A_{u} consecutive time slots, it creates a new RW (green). Similarly, when node v v has not been visited for A v A_{v} time slots, it creates another new RW (orange). The blue trajectory connects these RWs and forms a chain.
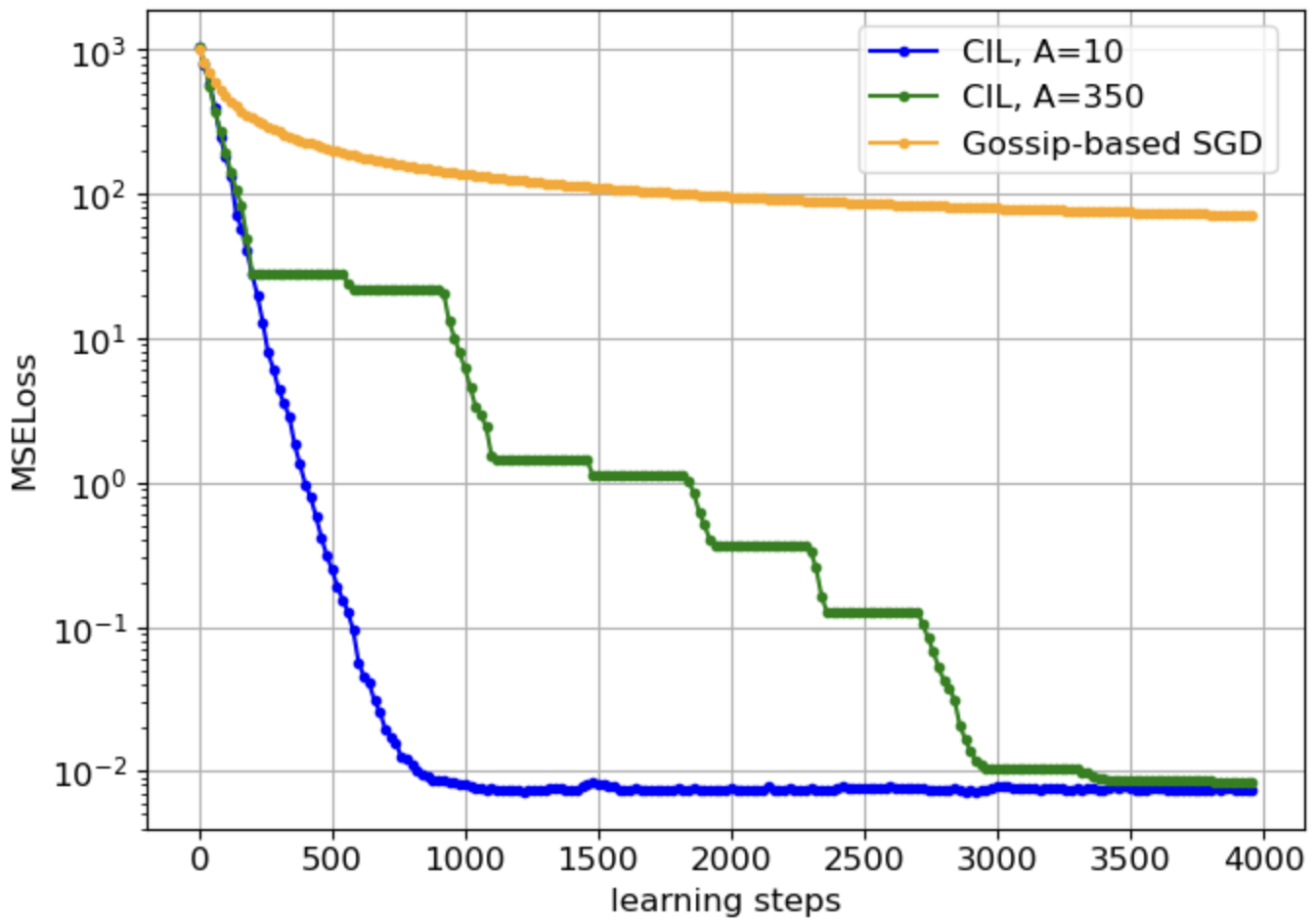
Fig 4: Figure 4 : Loss v.s. learning steps on a complete graph: comparison between CIL and gossip-based SGD.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
The theoretical analysis focuses on a single stealthy attacker for clarity; extensions to multiple attackers are discussed and validated empirically but require more detailed analysis. Choosing the creation threshold and creation probability trades off communication overhead versus recovery speed — aggressive settings speed recovery but increase traffic. Convergence still occurs but can be biased: premature token terminations skew the learned solution; the paper bounds that deviation but it is not zero.
The Details
Nodes run token-based (random-walk) decentralized learning where a single token carries the active update. A stealthy attacker (called Pac-Man) can probabilistically terminate any token that visits it, quietly eliminating tokens over time and halting learning. Rather than trying to detect or duplicate tokens globally, let each benign node track when it was last visited and, if it hasn’t seen a token for a preset interval, probabilistically create a new token by copying its cached last token. This Create-If-Late rule is entirely local, requires no global parameter estimation, and can be tuned via two intuitive knobs: the wait threshold and the creation probability.
The mechanism guarantees three useful properties: tokens never go permanently extinct (they are recreated after a bounded wait), the total number of tokens stays bounded (so the network won’t be flooded), and decentralized stochastic gradient descent run on these tokens converges despite attacks, with a provable bound on the bias introduced by premature terminations. Analysis handles the complex dependencies that arise when nodes create tokens based only on local visit history. Experiments on synthetic and public benchmarks confirm the theory: the system recovers after all tokens are wiped out and tolerates multiple malicious nodes (tested up to 10% in a 100-node graph). The main practical trade-off is extra communication when creation is frequent; system designers can pick the threshold and creation probability to balance speed versus overhead. malicious nodes
Need expert guidance?We can help implement this
Credibility Assessment:
Includes Parimal Parag (h-index ~14) indicating an established researcher and some technical credibility, though venue is arXiv.