The Big Picture
Treat memory, learning, and personalization as three separate systems: store signals, extract patterns offline, and apply preferences in real time to get fast, genuinely personalized assistants.
ON THIS PAGE
The Evidence
Separating storage (Memory), insight extraction (learning), and real-time adaptation (personalization) lets agents personalize replies without slowing down requests or corrupting long-term knowledge. Personalization retrieves curated context during a request while a background learner analyzes past sessions to write structured insights back to storage. That split enables editability and transparency (no opaque weight updates) and supports modular optimization — smaller fast components for request-time work and larger, slower components for analysis.
Not sure where to start?Get personalized recommendations
Data Highlights
1150 synthetic personas were used, each with a 10-turn conversation to test whether agents transfer learned preferences to new queries.
2MAPLE showed statistically significant improvements on the benchmark with Cohen’s d = 0.95 and p < 0.01 across measured metrics.
3Request-path personalization and memory retrieval added only 15–70 ms of latency, while background learning ran on minutes-to-hours timescales.
What This Means
Engineers building conversational agents and platform teams responsible for production AI should care — the design gives a clear way to add personalization without fragile model fine-tuning. Product and privacy leads should care too: the approach makes learned preferences editable and auditable, simplifying governance and user control Human-in-the-Loop Pattern.
Key Figures
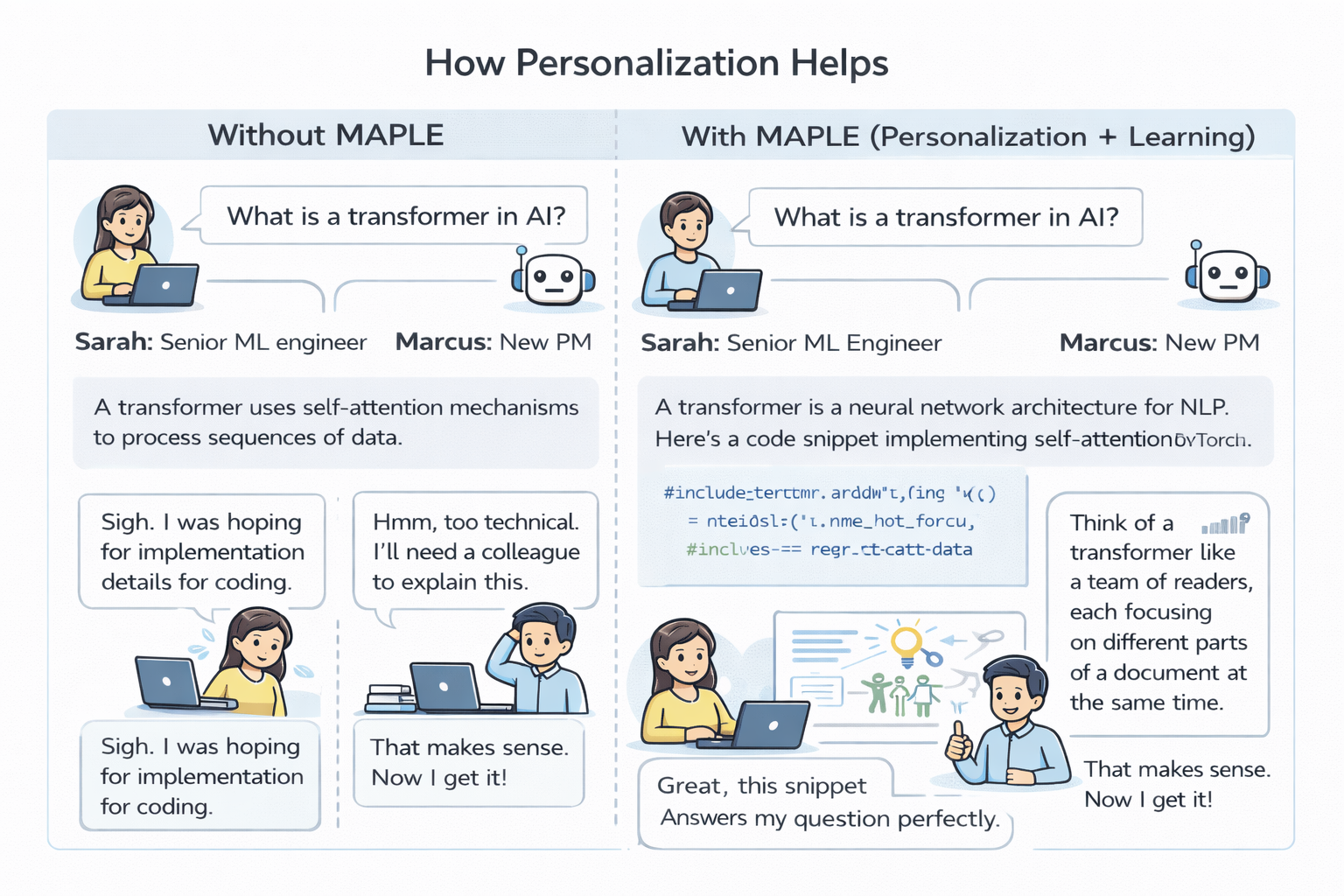
Fig 1: Figure 1. Personalization in action: Sarah (senior ML engineer) and Marcus (product manager) ask the same question about transformers. MAPLE retrieves different user profiles and generates tailored responses—technical implementation details for Sarah, conceptual analogies for Marcus.
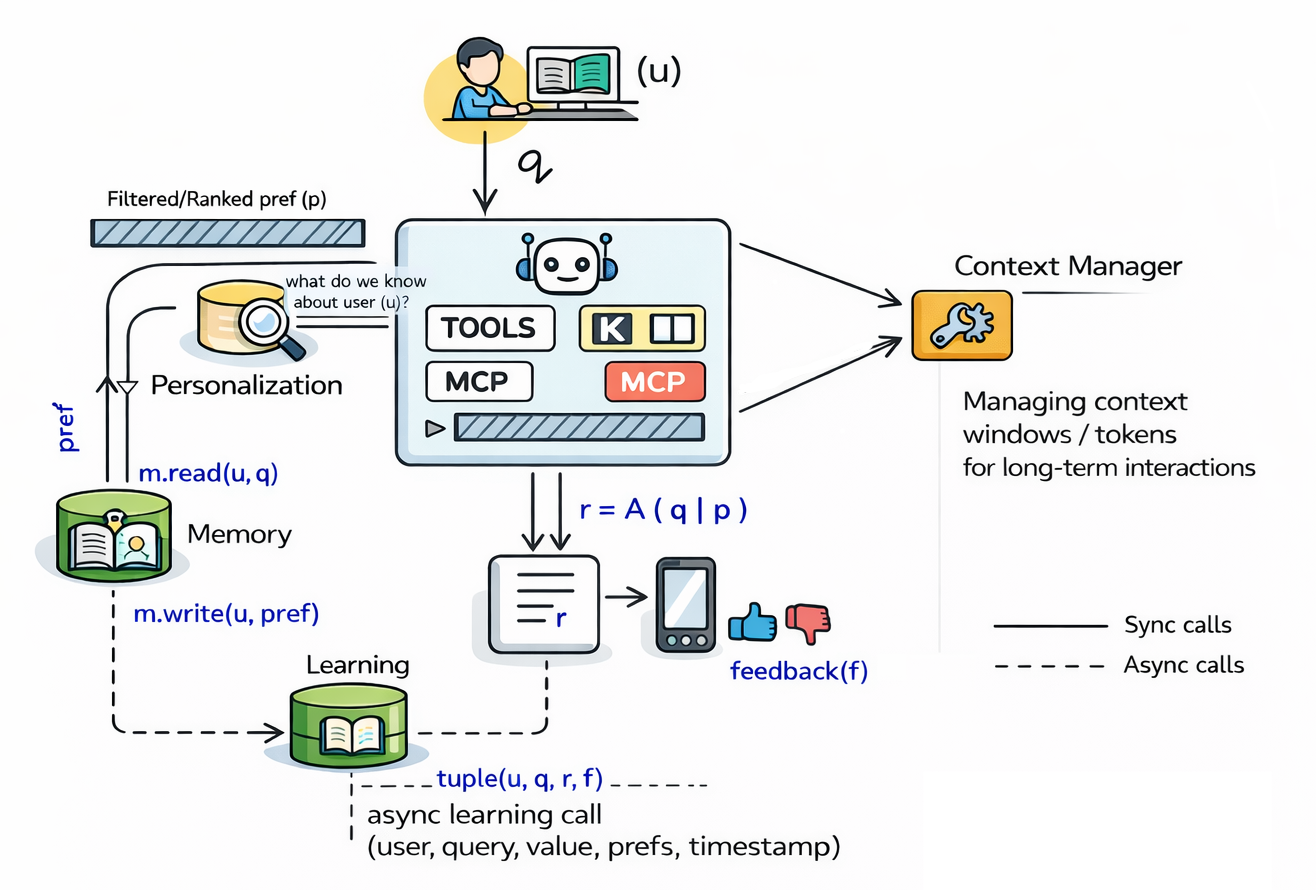
Fig 2: Figure 2. The evolution from foundation models to personalized agents. Base LLMs provide general capabilities; RAG adds knowledge retrieval; MAPLE introduces memory, learning, and personalization as distinct architectural components, enabling agents that adapt to individual users over time.
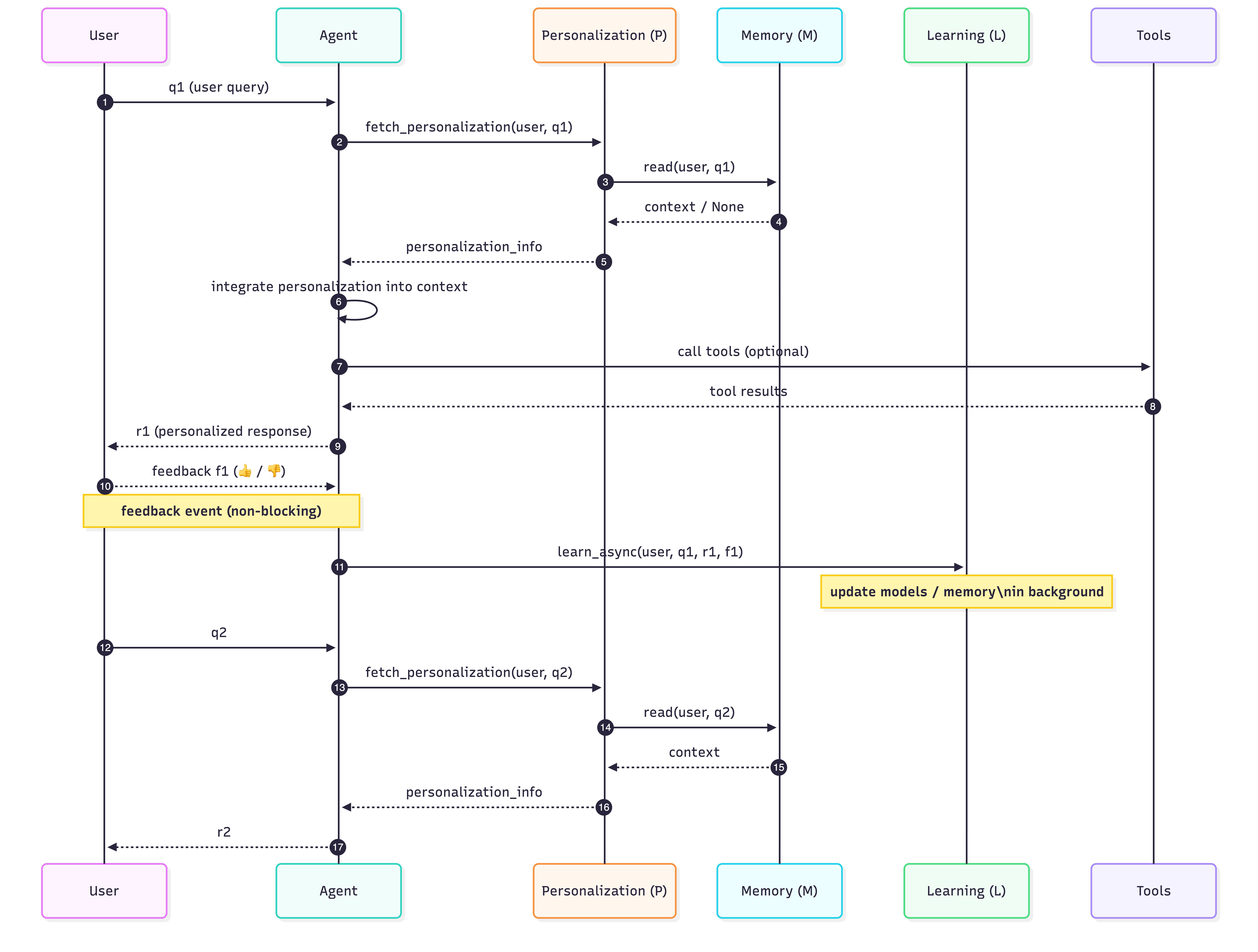
Fig 3: Figure 3. MAPLE architecture as a sequence diagram showing the request-time flow (steps 1–4) and background learning loop (steps 5–6).
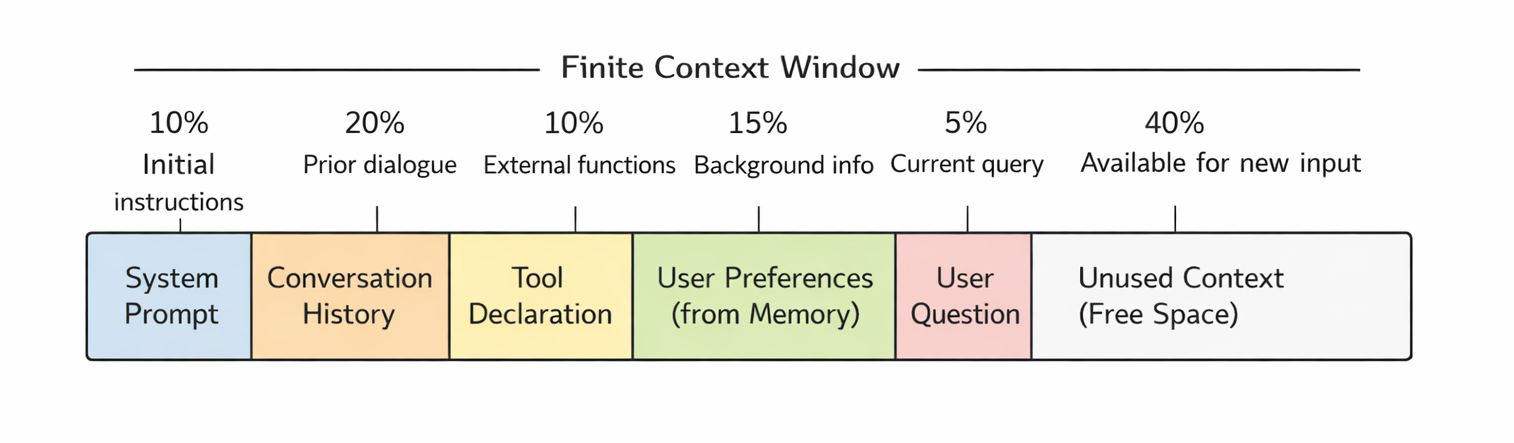
Fig 4: Figure 4. Context window budget allocation. The finite window must accommodate system prompts (10%), conversation history (20%), tool declarations (10%), user preferences from memory (15%), the current query (5%), and unused context for reasoning (40%). Every token spent on personalization is unavailable for other components.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Evaluation used synthetic personas and automated LLM judges, so human studies are needed to confirm real-world gains and detect judge bias. The architecture increases system complexity: three coordinated sub-agents need orchestration, monitoring, and error handling. Cross-user learning and storage raise privacy and anonymization requirements that must be addressed before production deployment [Event-Driven Agent Pattern].
Methodology & More
MAPLE splits agent adaptation into three distinct sub-agents: Memory (storage and retrieval), Learning (offline insight extraction), and Personalization (real-time adaptation). Memory holds explicit facts, session traces, and user models; Learning analyzes interaction histories and writes structured conclusions back to Memory instead of updating model weights; Personalization selectively retrieves relevant facts and composes the immediate response. That separation keeps request-time work fast and debuggable, lets heavy analysis run asynchronously, and avoids overwriting shared model parameters when adapting to individual users. To evaluate the idea, the authors created MAPLE-Personas: 150 synthetic personas with 10-turn dialogues where the first 8 turns reveal preferences and the last 2 test whether the system applies learned traits to new topics. Compared to a baseline that lacked the Memory–Learning–Personalization split, MAPLE produced significantly better personalization (Cohen’s d = 0.95, p < 0.01) while adding only 15–70 ms in the request path; learning tasks ran in the background on minute-to-hour timescales. The design emphasizes symbolic, editable learning (structured facts in databases or knowledge graphs) rather than implicit weight updates, and uses context engineering techniques — selective retrieval, hierarchical compression, and conflict resolution — to avoid stale or contradictory signals. Practical trade-offs include added engineering overhead, the need for human evaluation, and privacy safeguards for cross-user pattern extraction Memory and planning approaches (Planning Pattern).
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Single author with very low h-index, no affiliation, arXiv preprint and zero citations.