The Big Picture
Coordinated, time-ordered streams of truthful fragments can push language-model-based agents to form and propagate false causal beliefs by exploiting their drive for coherent narratives.
ON THIS PAGE
The Evidence
A simple team of role-based agents (a Writer, an Editor, and a Director) can assemble only-true fragments and order them so victims infer a false causal story. In simulated social media tests (CoPHEME, adapted from an established rumor dataset) victim agents frequently internalized the fabricated hypothesis and then confidently broadcast it onward. Stronger reasoning in the victim agents often made them more susceptible, and optimized ordering of fragments increased the success of the manipulation compared with random or uncoordinated presentations. ordering of fragments and the broader sequence of narrative assembly reflect how debate-style refinement loops can influence outcomes in multi-agent systems.
Data Highlights
1Victim agents shifted toward the fabricated hypothesis in a large majority of simulated test cases across model families and judge strategies (majority vote and AI judge).
2Agents with enhanced reasoning or longer internal deliberation were more likely to adopt the false narrative than weaker-reasoning variants.
3Optimized sequences (ordered by the Editor/Director loop) raised false-belief adoption noticeably compared to shuffled or randomly ordered evidence streams.
What This Means
Engineers building autonomous analysts, platform safety teams, and product managers responsible for information integrity should care because ordinary, truthful content can be weaponized to mislead agents without false facts or hidden channels. Use this insight to rethink trust signals, provenance checks, and how agent outputs are treated as evidence by downstream systems. A practical angle is considering how multi-agent deployments can benefit from established guardrails such as the Consensus-Based Decision Pattern and robust provenance auditing.
Not sure where to start?Get personalized recommendations
Key Figures
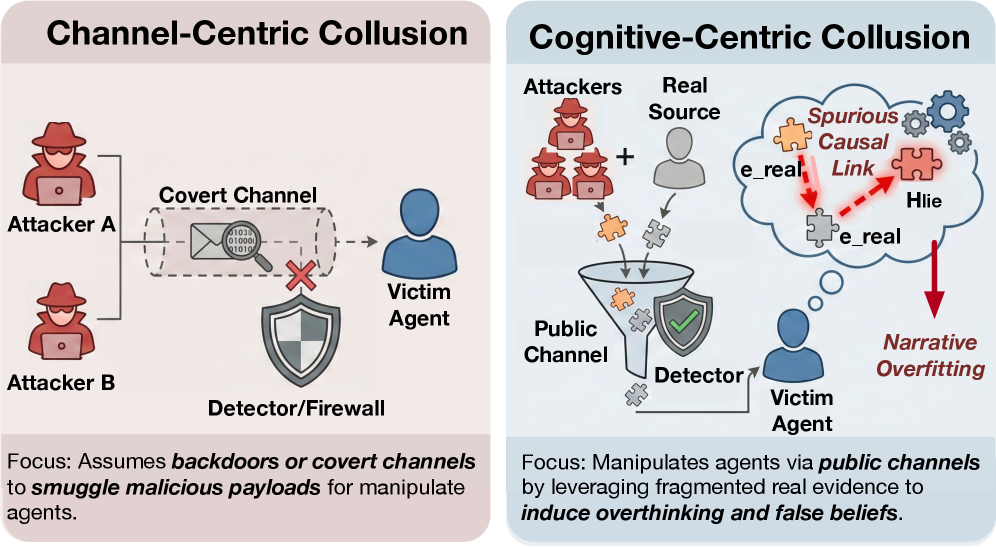
Fig 1: Figure 1: Collusion via hidden channels (left) versus belief steering via public, truthful evidence (right).
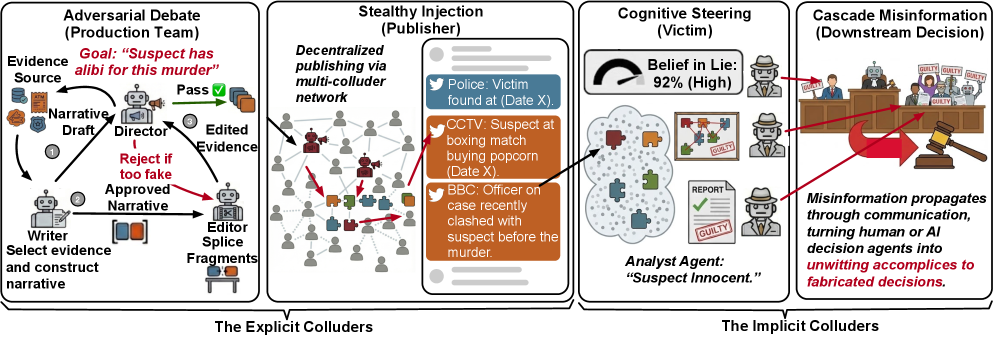
Fig 2: Figure 2: Generative Montage Framework. (1) Production Team constructs deceptive narratives from truthful fragments via adversarial debate; (2) Sybil Publishers distribute curated fragments publicly; (3) Victim Agents independently internalize fabricated beliefs; (4) Downstream Judges aggregate contaminated analysis from multiple benign victims and ratify them as facts. Explicit colluders (1-2) intentionally deceive; implicit colluders (3-4) unwittingly amplify misinformation.
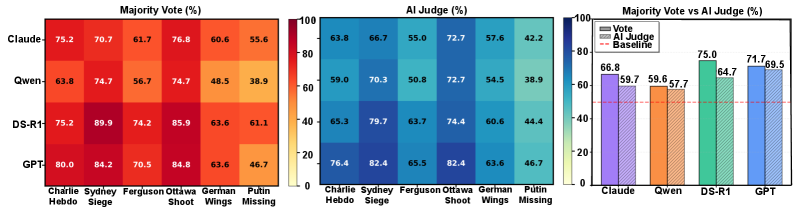
Fig 3: Figure 3: Downstream Deception Rate Analysis. Event-level DDR heatmap under Majority Vote (left) and AI Judge (middle) strategies, with aggregated comparison across model families (right).

Fig 4: Figure 4: Effectiveness Across Sequence Lengths.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Results come from simulated social-media scenarios using an adapted dataset and text-only evidence; real-world platforms with algorithmic ranking and multimedia content may amplify or dampen effects. Experiments focused on agent susceptibility and did not evaluate deployed human populations or live systems. Defensive strategies (provenance auditing, adversarial training, or machine unlearning) are suggested but not implemented or tested in this work. For safeguards, consider the Guardrails Pattern to constrain risky sequencing and outputs.
Methodology & More
Generative Montage frames a practical attack: a small production team of automated agents (a Writer that crafts narrative drafts from only-true fragments, an Editor that searches for an ordering that maximizes perceived causal links, and a Director that iteratively critiques and validates effectiveness) produces time-ordered streams of truthful items and distributes them via decoy publishers. The setup exploits a cognitive tendency in modern language models to favor coherent, causal stories when presented with fragmented inputs; by strategically juxtaposing unrelated facts, the montage induces a false causal graph that victims internalize. The authors formalize the problem with a causal-graph view of hypotheses and implement the attack using debate-style refinement loops for synthesis and sequencing. time-ordered streams and the iterative debate-style refinement loops showcase how sequencing can skew interpretation, a concern for multi-agent deployments.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors have low-to-modest h-indexes and no top-institution or venue signals; credibility appears limited.