The Big Picture
A-MapReduce turns large, messy search tasks into an explicit, parallel workflow and reuses past execution patterns—boosting accuracy while cutting runtime and cost.
ON THIS PAGE
The Evidence
Wide search works better when treated as a structured, parallel job instead of a long text conversation. A-MapReduce organizes a query into a schema-driven map step (many small retrievals) and a reduce step (merge into a single table), then stores past execution traces to guide future runs. That combination improves item-level accuracy and reduces redundant retrieval. Across benchmarks it delivered consistent accuracy gains and large runtime and cost savings compared with other multi-agent set-ups.
Data Highlights
15.64% to 27.62% absolute improvement in Item-level F1 across WideSearch and DeepWideSearch benchmarks
245.8% lower running time versus representative multi-agent baselines
3$1.10 average cost savings per task compared with those baselines
What This Means
Engineers building multi-agent search or evidence-aggregation systems who need reliable, repeatable coverage across many sources. Technical leaders evaluating agent orchestration tools for enterprise search, research assistants, or comparative analysis workflows will find better accuracy and lower operational cost. Researchers exploring how agents can reuse execution patterns across tasks can use the experiential memory idea to speed up learning.
Not sure where to start?Get personalized recommendations
Key Figures
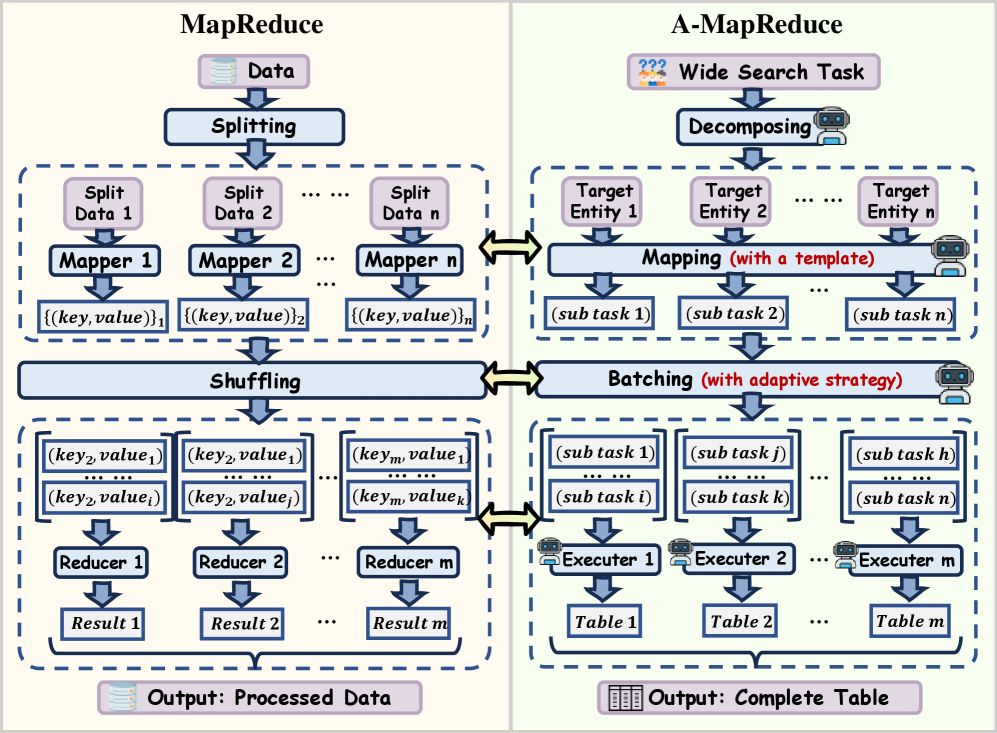
Fig 1: Figure 1 : Structural isomorphism: A-MapReduce mirrors the MapReduce pipeline via a one-to-one operator corresponding.
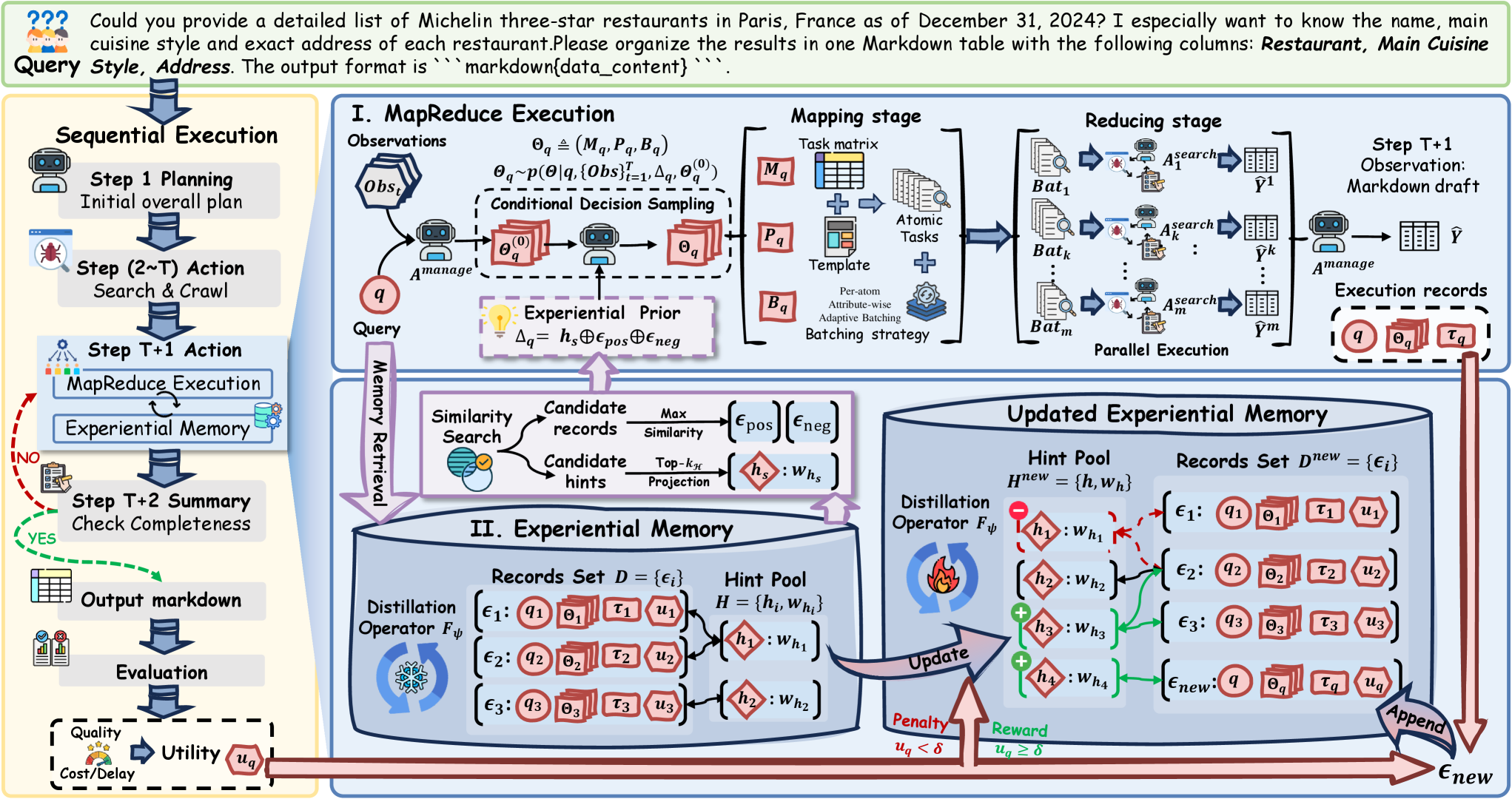
Fig 2: Figure 2 : Overall workflow of our A-MapReduce . Given a wide-search query, our framework takes lightweight sequential execution, then retrieves experiential prior as a decision anchor from experiential memory and samples a conditional MapReduce decision. It then decomposes the query into atomic tasks for batched parallel execution and reduces partial results into a single structured output. After completion, environmental feedback updates the experiential memory, enabling continual cross-task refinement of execution decisions.

Fig 3: (a) Cost–Performance on WideSearch and DeepWideSearch.
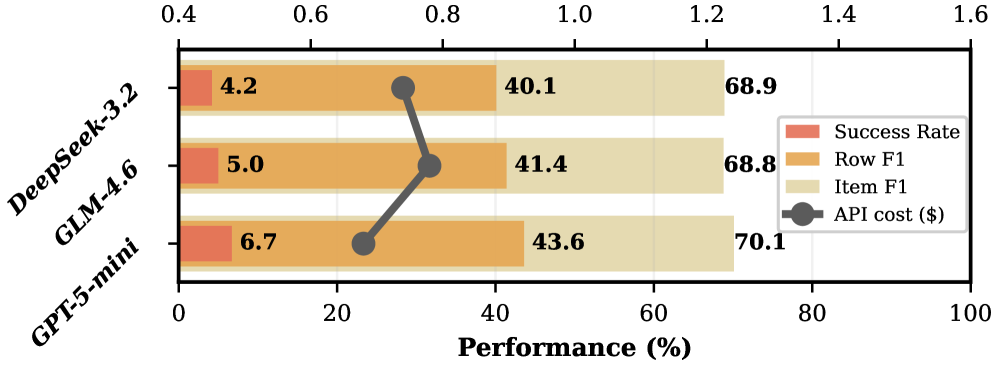
Fig 4: (a) Backbone robustness.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Results come from specific wide-search benchmarks and an implementation using a particular model backbone; performance may vary on other domains or with different LLMs. The experience memory is updated using only quality signals (not direct cost or delay), so evolved strategies may prioritize correctness over raw efficiency. As with any web-based retrieval system, outputs depend on source quality and still need source verification and human oversight.
Methodology & More
Wide-search tasks ask agents to find many entities and fill a structured table of attributes—so failures usually come from missing entries or redundant retrievals when work is coordinated via long chat histories. A-MapReduce reframes execution as an explicit Map (many small, parallel retrieval tasks) and Reduce (merge into a schema-consistent table) process. The framework maintains a persistent task representation (the schema and coverage tracking), decomposes queries into atomic retrieval batches, runs them in parallel, and merges results into a unified output, which avoids the brittle long-horizon context that breaks sequential multi-agent approaches. A-MapReduce adds an experiential memory that stores past execution trajectories as reusable hints. For each new query the system retrieves similar past decisions and conditions its map/reduce decomposition on them, gradually refining which decompositions work best for what kinds of queries. Evaluated on five benchmarks and compared with strong single-agent and multi-agent baselines, A-MapReduce yielded 5.6–27.6% absolute Item-level F1 gains, cut runtime by 45.8%, and saved about $1.10 per task on average. Practically, that means fewer missed items, less redundant work, and repeatable execution patterns that improve over time—useful for large-scale evidence aggregation, research assistants, and enterprise search pipelines. Multi-Agent System
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors show very low h-indices and no listed affiliations or strong venue signals.