The Big Picture
Small models equipped with the right external tools and a lightweight agent structure can match or beat much larger single models on agentic tasks; thoughtful tool coordination matters more than extra internal 'thinking.'
ON THIS PAGE
The Evidence
Small models (4B parameters) with tool-augmented agent pipelines can rival or exceed much larger monolithic models (up to 32B) on the GAIA agent benchmark. Using external tools (search, code execution, memory) gives more consistent gains than adding explicit internal deliberation. Internal deliberation thinking helps some instruction-tuned small models but full internal deliberation often increases tool calls and can harm accuracy—especially for smaller models and long-horizon tasks—because it breaks tool coordination.
Data Highlights
1Web search accounted for roughly 70–90% of all tool calls across setups, reflecting GAIA's retrieval-heavy tasks.
2Planner thinking raised memory (Mind-Map) usage to as much as 29.4% of calls for the 8B model, showing increased tool diversity.
3Small 4B models with tools matched or outperformed 32B monolithic models on GAIA tasks, demonstrating tool augmentation can substitute for scale.
What This Means
Engineers building multi-agent systems and leaders deciding where to spend compute and engineering effort should care: investing in robust tool integrations and better tool coordination can beat simply using a larger model. Researchers evaluating agent trust or agent-to-agent behavior will find that tool choice and orchestration drive reliability more than model size alone.
Not sure where to start?Get personalized recommendations
Key Figures

Fig 1: (a) No Thinking
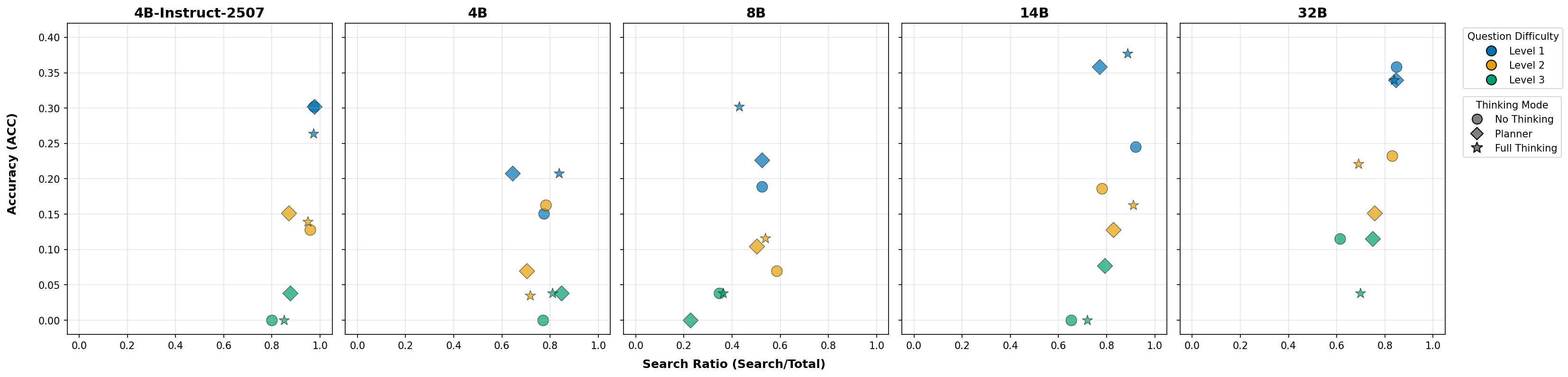
Fig 2: (a) Web-Search usage
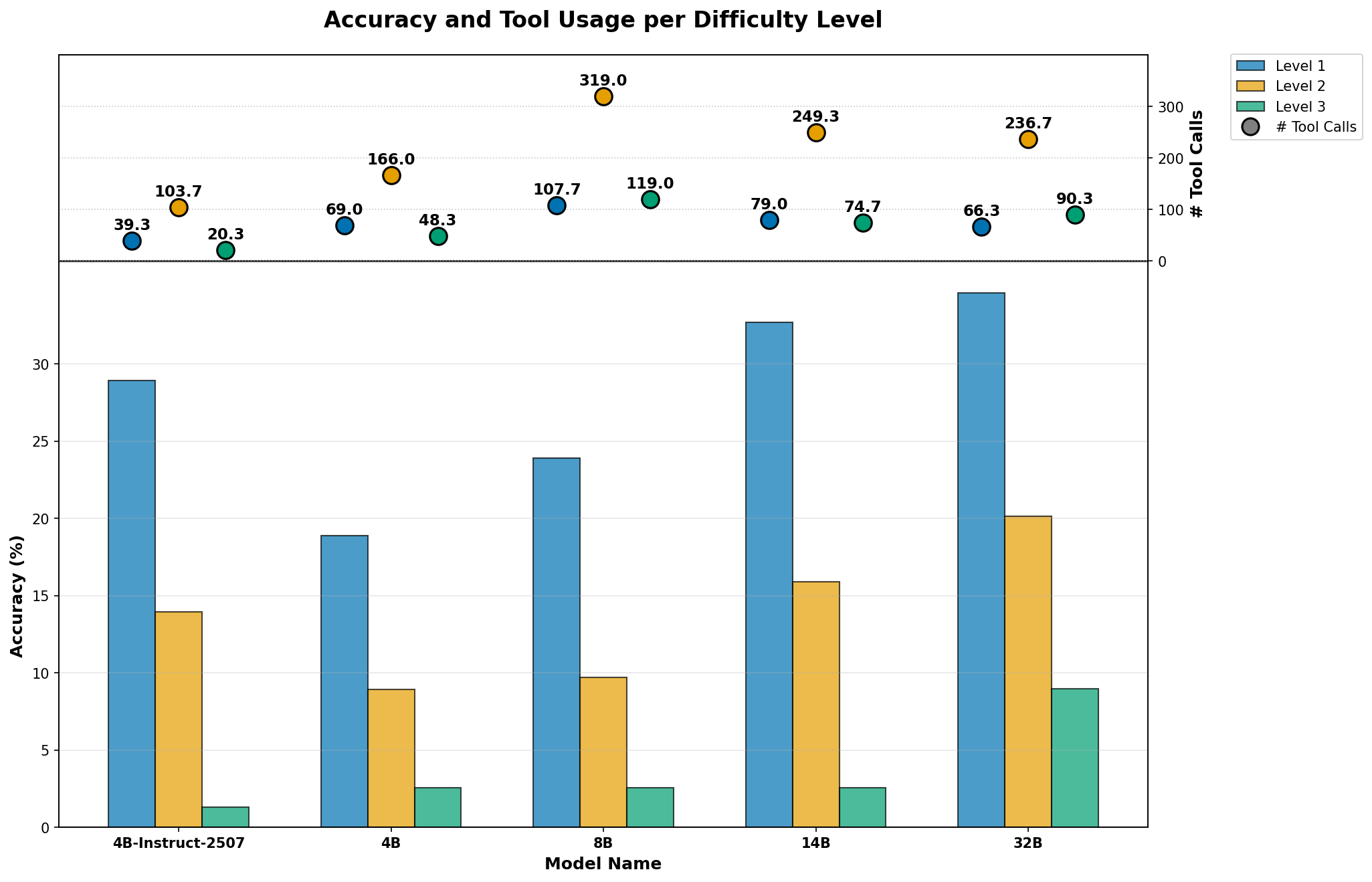
Fig 3: Figure 3: Average accuracy vs. total tool calls per difficulty level. Tool usage peaks at Level 2, while Level 3 accuracy drops despite similar or lower tool calls, suggesting early planning errors rather than execution issues.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreKeep in Mind
Results come from the GAIA benchmark and a limited set of open-source backbone models (4B–32B); outcomes may differ with other benchmarks or higher-quality retrieval and tool implementations. Experiments used a single shared model instance re-roled via prompts, which may not reflect fully parallel multi-model deployments. Multi-model deployments explicit reasoning strategies were fixed; dynamic or selective thinking policies might reduce the coordination failures reported here.
Methodology & More
The study tested whether many small, tool-enabled agents can outperform a single large language model on agent-style tasks. Using models ranging from 4 billion to 32 billion parameters and the GAIA benchmark (three difficulty levels), the setup replaced a single monolithic system with an agentic pipeline: a planner, tool-invoking agents (web search, code executor, external memory), and an answer controller. To stay realistic for common hardware, the experiments reused one shared model instance and re-assigned roles through specialized prompts rather than running many independent models in parallel.
Key findings show tool augmentation offers the clearest wins: small models with good tool orchestration matched or beat much larger models without tools. Effective performance depended less on how many tool calls were made and more on selecting the right tool at the right time—Web Search dominated calls (70–90%), while planner thinking increased tool diversity (e.g., memory use rose to 29.4% for an 8B model). Adding full internal deliberation often increased tool calls and introduced coordination errors (skipping computation, formatting drift, or call loops), which hurt accuracy on computation-heavy and long-horizon tasks. Practical takeaway: treat explicit internal thinking as a controllable resource—use it selectively for planning or constraint checks, and prioritize robust tool interfaces and coordination logic over simply scaling model size. Coordination
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Includes Maarten de Rijke (well-known researcher) alongside other authors; despite arXiv venue and missing affiliations here, recognized author boosts credibility.