The Big Picture
A telemetry-driven update manager can automatically delay risky model upgrades for millisecond-sensitive functions while rolling out improvements to less-sensitive services, preserving stability and overall utility.
ON THIS PAGE
The Evidence
A self-learning update manager that watches runtime telemetry and consults a version repository can decide when to swap in newer models to balance accuracy, stability, and service delays. A reinforcement-learning policy learned to prioritize stability for the most delay-sensitive apps (millisecond dApps), preserving their latency, while upgrading xApps and rApps at times that minimize delay impact. Always-updating gives the highest raw accuracy but hurts operational stability; never-updating preserves stability but misses accuracy gains. The learned policy achieves near-best stability for delay-sensitive workloads and better accuracy than random or load-based baselines for less-sensitive workloads.
Data Highlights
1Each major model release increased inference accuracy by ~2%, reduced replica stability by ~2%, and reduced per-request service time by ~7%.
2Median end-to-end delays observed: dApps ≈ 10–12 ms, xApps ≈ 490 ms, rApps ≈ 4.11 s.
3The reinforcement-learning update policy produced stability for dApps close to the ideal (stability ≈ 1, similar to never-updating) while achieving higher xApp/rApp accuracy than random or load-based update strategies.
What This Means
Network operators and platform teams building cloud-to-edge AI should care because uncontrolled updates can either break tight real-time guarantees or leave networks using stale models. Engineers building radio-control apps (millisecond-, sub-second-, and multi-second control loops) can use a telemetry-driven update manager to automate safe rollouts. MLOps teams at telco operators can adopt learned update policies to trade off accuracy gains against service continuity automatically.
Not sure where to start?Get personalized recommendations
Key Figures
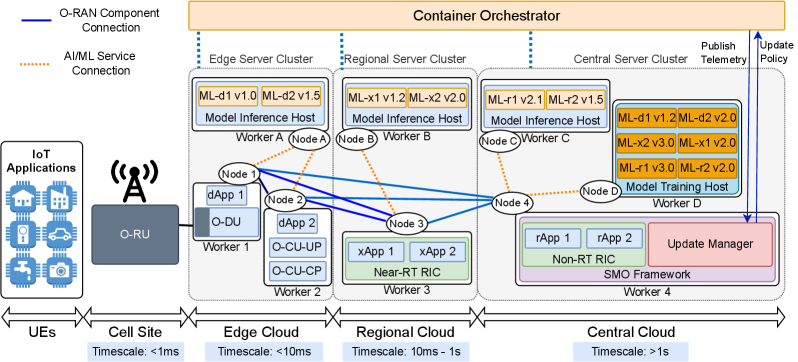
Fig 1: Figure 1 : O-RAN compliant reference architecture with self-learning and ML model versioning.
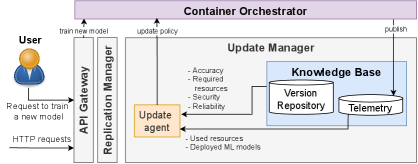
Fig 2: Figure 2 : ML Update Manager
![Figure 3 : A simplified ML versioning flow diagram for massive MIMO beamforming optimization, based on [ 9 ]](https://arxiv.org/html/2601.17534v1/x3.png)
Fig 3: Figure 3 : A simplified ML versioning flow diagram for massive MIMO beamforming optimization, based on [ 9 ]
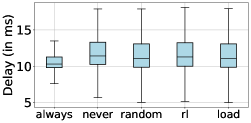
Fig 4: (a) ORAN-dApp
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreLimitations
Results come from simulations with a simplified topology and synthetic arrival/service processes; real deployments have more variability and unknown failure modes. Security concerns were modeled as a quality score but not exhaustively tested—malicious or poisoned updates need dedicated defenses. Hyperparameters, reward weights, and the assumed cost of spawning replicas influence the learned policy and must be tuned per site before production use. Malicious or poisoned updates
Methodology & More
A multilayer reference architecture links cloud training with multi-layer inference: models are trained in the cloud, stored with quality metadata in a version repository, and deployed to inference hosts used by three control loops (millisecond-level dApps, ~100s-of-ms xApps, and multi-second rApps). An ML Update Manager Update Manager continuously collects telemetry (delays, load, version availability) and runs an Update Agent that either keeps running replicas on the current model or replaces them with a newer version. Each model version carries resource footprints and quality scores (accuracy, stability, security); updates can change inference time, replica stability, and resource needs.
The Update Agent was implemented as a reinforcement-learning (Q-learning) policy and compared against four baselines: always update, never update, random update, and a server-load-based rule. Simulations used a layered cloud/edge topology with six representative models and realistic control-loop delay budgets. Findings show the learned policy favors stability for latency-critical dApps (keeping median delays in the 10–12 ms range) while accepting updates for xApps and rApps when they have minimal latency impact (xApps ~490 ms, rApps ~4.11 s). Always-updating maximizes accuracy but lowers stability; the learned policy achieves a better practical trade-off—near-ideal stability for millisecond-sensitive workloads and improved accuracy for less constrained ones. Practical takeaway: closed-loop, telemetry-driven versioning is effective to automate safe model rollouts in edge networks, but real deployments need site-specific tuning and stronger security checks.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Includes an author with h-index ~27 and other experienced researchers; stronger credibility despite arXiv venue.