The Big Picture
Networks of language models acting as specialist agents speed prototyping and solve fragmented data problems, but inconsistent outputs and governance needs mean extra work before safe production use.
ON THIS PAGE
The Evidence
Specialist agents powered by language models let teams divide work—searching, querying, and drafting—so complex data tasks get built in weeks instead of months. In three real-world pilots (telecom security, national asset tracking, and customer service) the approach proved platform-agnostic and easy to iterate, with useful analyst feedback. Major downsides are unpredictable model outputs, risk of mistaken facts, and higher compute and governance overhead when moving to production. The paper formalises repeatable agent design patterns (tools, reasoning engine, orchestration, and memory) and shows where organisations should add checks and validation. This benefits from a strong guardrails and orchestration backbone.
Not sure where to start?Get personalized recommendations
Data Highlights
1Prototype and user-acceptance testing were completed within 1 month using the multi-agent approach, while prior contractors failed to deliver after several months.
2At least 86 major large language model releases were recorded since 2023, highlighting rapid ecosystem change that MAS teams must track.
3Publicly disclosed software vulnerabilities climbed to over 46,000 annually by 2025, demonstrating the scale of data SOCs must filter and correlate.
What This Means
AI engineers and platform teams building conversational or data-integration tools can use these patterns to prototype faster and keep components modular. Security operations leaders, data platform owners, and product managers should evaluate agent-based designs to automate cross-source search and triage while planning for governance and validation work before rollout. Plan for governance and validation using established patterns like governance.
Key Figures
![Figure 1: Timeline illustrating the cumulative release of major LLM models by ten leading AI companies since 2023 [ luyen2025howwell ] .](https://arxiv.org/html/2601.03328v1/llm-timeline-colourblind.png)
Fig 1: Figure 1: Timeline illustrating the cumulative release of major LLM models by ten leading AI companies since 2023 [ luyen2025howwell ] .

Fig 2: Figure 2: Workflow loop of a ReAct agent, depicting iterative reasoning and action execution of key stages, enabling recursive reasoning through chain-of-thought reasoning.

Fig 3: Figure 3: Abstract representation of a Multi-Agent System configured as a Single Information Environment (SIE). The diagram illustrates dynamic control flow, agent handoff strategies, and human-on-the-loop oversight for coordinated data retrieval and decision-making.
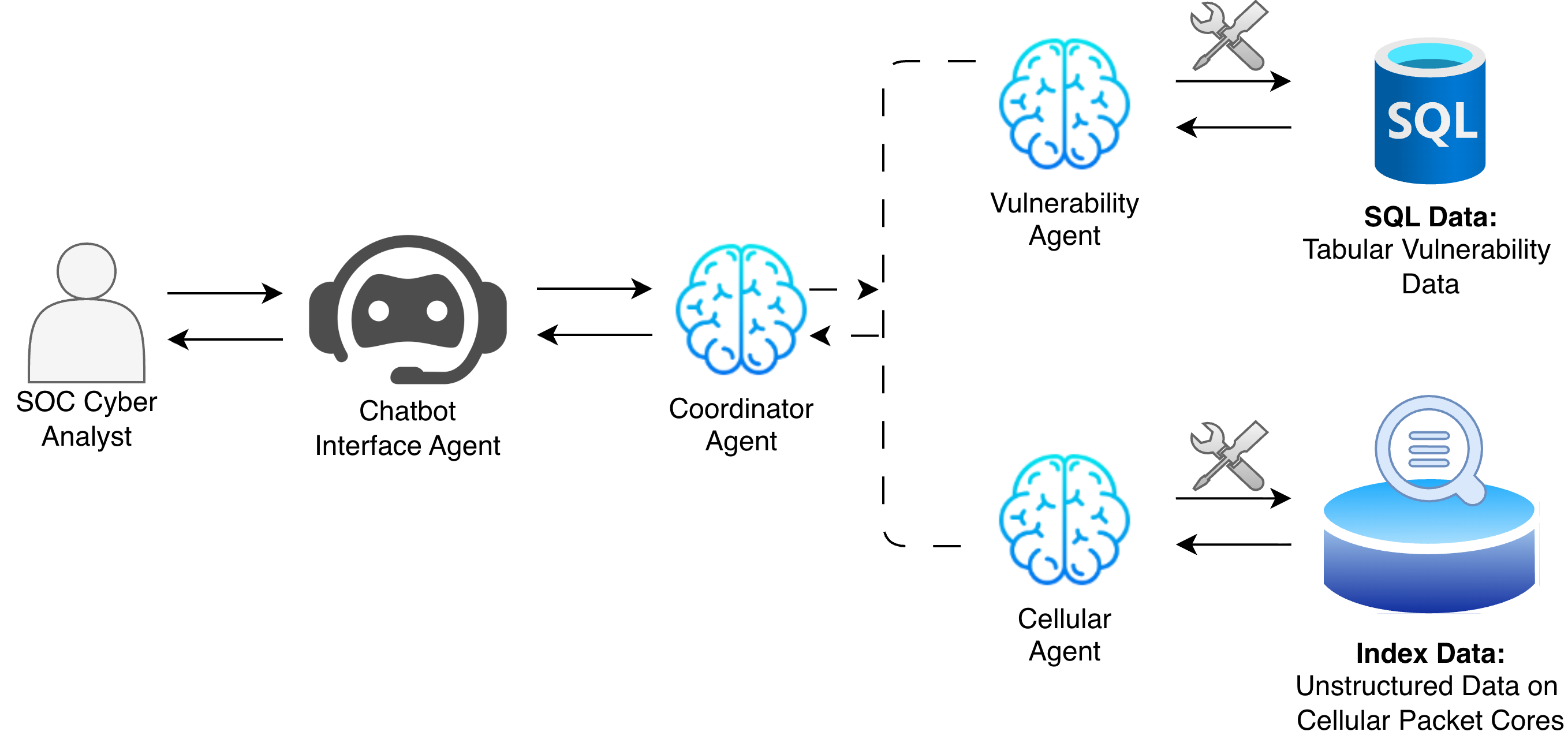
Fig 4: Figure 4: MAS architecture deployed in a Telecom SOC case study. The design integrates specialised agents for threat intelligence retrieval and correlation, coordinated through a central supervisor agent, with a conversational interface for analyst interaction.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Language models still produce variable and sometimes incorrect outputs, so systems need verification steps and human review for high-stakes tasks. Coordination overhead rises as the number of agents grows; local optimisations can conflict with global goals and cause error propagation. Expect higher compute costs and nontrivial engineering to harden prototypes for production-grade reliability and compliance. Emphasize verification steps and human review with verification guidelines.
Methodology & More
The study defines a practical design pattern for multi-agent systems where each agent is a specialist powered by a language model, a suite of tools (databases, search, code execution), an orchestration layer, and short- and long-term memory. Using that template, the team built three proof-of-concept systems across telecom security, national asset management, and customer service automation. Developers used conversational front-ends and a coordinator agent coordinator agent to hand tasks to specialist agents (for example, one agent ran SQL queries while another performed similarity search on unstructured threat reports). The approach proved fast to iterate and platform-agnostic, often packaged as portable containers for on-premises use. The memory component can leverage strategies captured in memory handling.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors have low h-index values and no affiliations listed — some minimal recognition but limited signals.