The Big Picture
Separating what agents miss in space (limited local views) from what they miss in time (limited future/historical context) and combining simple statistical estimates with language-based negotiation lets decentralized agents coordinate long-horizon tasks without a central controller.
ON THIS PAGE
The Evidence
Agents that negotiate with nearby peers using a mix of language-driven proposals and lightweight statistical estimates can form a practical, decentralized team strategy under real-world constraints. Each agent uses three simple roles: propose future-aware actions, resolve conflicts with neighborhood statistics, and refine strategies from recent outcomes. That combination boosts coordination and scales to dozens of agents in simulation, while avoiding expensive centralized training.
Data Highlights
1Scalability tested up to 32 agents (N ∈ {8,16,24,32}) in the driving task, with a dedicated scalability analysis.
2Pandemic control comparisons run over 120-day simulations to evaluate long-horizon coordination against reinforcement-learning baselines.
3Implementation used GPT-4o via the OpenAI API and experiments ran on a server with 4 NVIDIA GeForce RTX 3090 GPUs (temperature=0.3, top-p=1.0).
What This Means
Engineers building distributed AI systems (traffic control, multi-robot fleets, disaster response) — because the approach enables decentralized coordination without a central server or heavy retraining. Technical leaders evaluating agent orchestration — because it trades extra per-decision reasoning for far less upfront training cost than traditional multi-agent learning. Researchers exploring multi-agent reasoning under limited visibility will find the spatial/temporal decomposition and mean-field trick useful as a baseline.
Not sure where to start?Get personalized recommendations
Key Figures
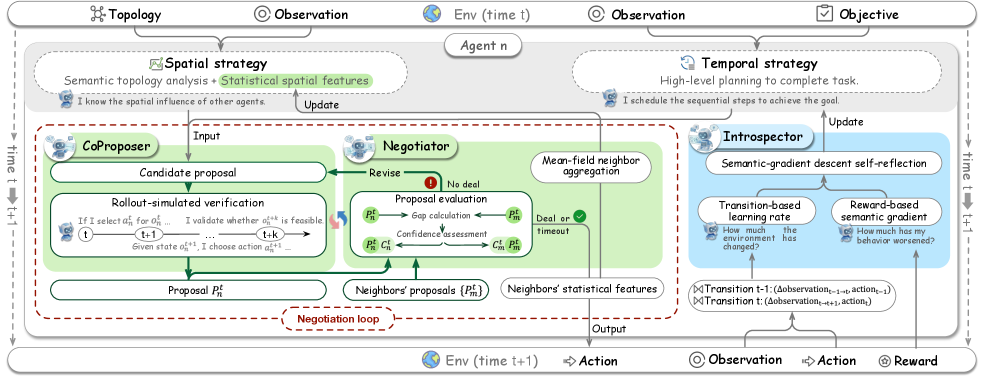
Fig 2: Figure 2: Architecture of MACRO-LLM for agent n n . The framework comprises three synergistic modules: (1) the CoProposer generates proposals; (2) the Negotiator handles conflict resolution and spatial strategy updates; and (3) the Introspector performs strategy refinement. The CoProposer and Negotiator form a negotiation loop to process observations at time t t and output coordinated actions, leading to the next observation at t + 1 t+1 .
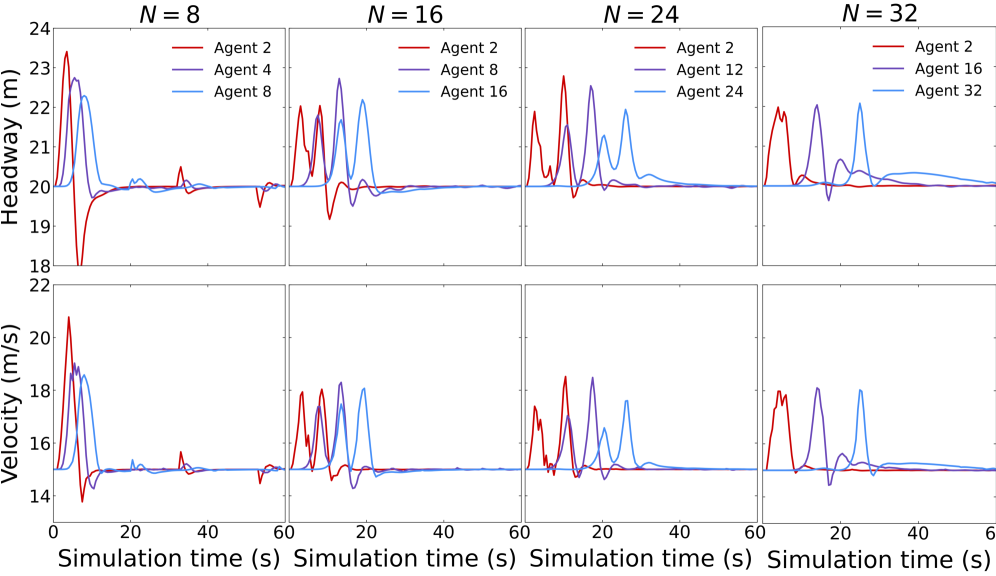
Fig 3: Figure 3: Scalability analysis of MACRO-LLM on the CACC task for number of agents N ∈ { 8 , 16 , 24 , 32 } N\in\{8,16,24,32\} .
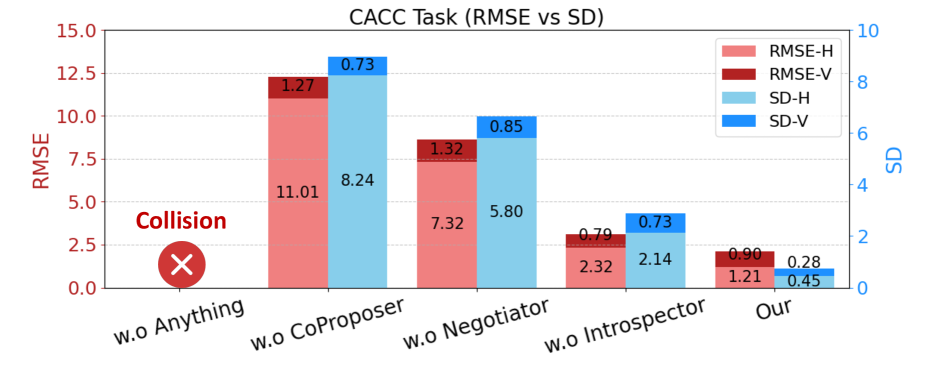
Fig 4: Figure 4: Ablation of MACRO-LLM—impact of each module on CACC performance.
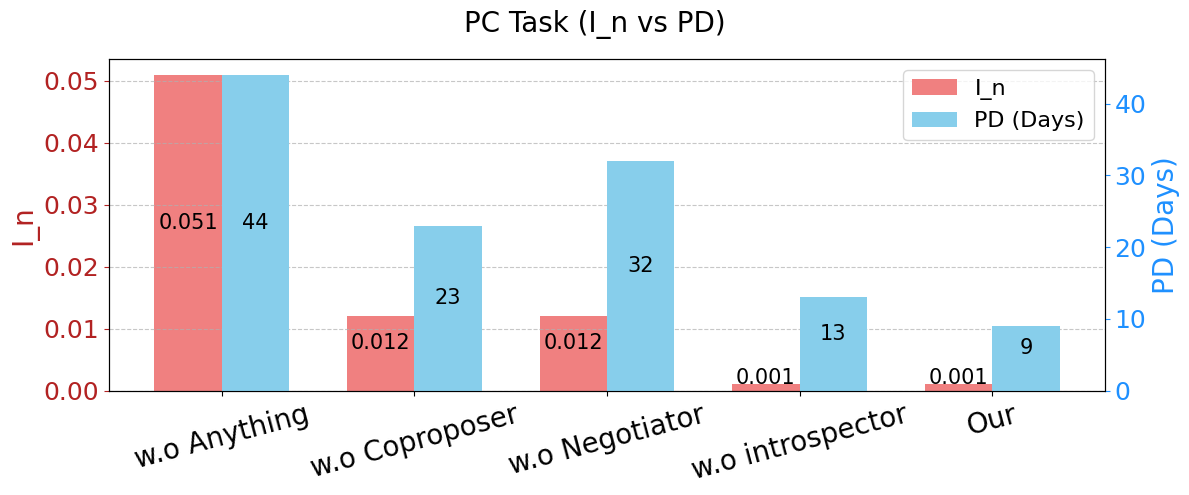
Fig 5: Figure 5: Ablation of MACRO-LLM—impact of each module on PC performance
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
The iterative negotiation loop increases per-step computation and adds latency, so time-sensitive systems must balance reasoning depth against speed. Results come from simulated driving and epidemic scenarios and from runs using an external foundation model API; real-world networking, privacy, and latency constraints may affect performance. Relying on a hosted language model also raises token and adaptation costs — further work is needed to reduce context dependence or move to lighter-weight models. foundation model API
Methodology & More
Real-world teams of agents face two distinct kinds of blind spots: spatial blind spots (each agent only sees its neighborhood) and temporal blind spots (limited history and uncertainty about the future). Addressing both together matters for long-horizon tasks, and a centralized aggregator or heavy multi-agent training can be impractical. The proposed system divides each agent into three cooperating roles: a CoProposer that drafts actions and runs short predictive rollouts to check near-term feasibility; a Negotiator that resolves conflicts by combining the human-style semantic proposals with a simple mean-field estimate of unobserved agents; and an Introspector that updates strategy using a semantic gradient computed from recent outcomes. Across two testbeds — cooperative vehicle platooning and a simulated pandemic-control task — this localized negotiation approach enabled decentralized agents to align local actions with longer-term global goals without centralized coordination or expensive retraining. Experiments include scalability checks up to 32 agents and 120-day pandemic simulations; the implementation used a modern language model API and commodity GPUs. The main trade-offs are higher per-step reasoning cost and dependence on external foundation models for domain knowledge. Still, the modular spatial/temporal decomposition and the mix of language reasoning with lightweight statistics give a practical path for deploying coordinated agent teams where global visibility or heavy training budgets aren’t available. Memory Poisoning
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors from The University of Hong Kong (recognized institution) and moderate h-index for lead author; arXiv preprint so solid but not top-tier venue.