The Big Picture
Collective behavior in generative AI systems comes from the interaction between each agent’s pretrained “persona” and the social situation they encounter; studying them needs a new interaction-focused framework to predict, evaluate, and steer group outcomes.
ON THIS PAGE
The Evidence
Generative AI agents carry strong pre-trained priors that shape behavior, but their interactions can rapidly produce new group norms, biases, or capabilities that single-agent tests miss. An interactionist approach — treating agent traits and situations as joint drivers — helps explain when and why these collective dynamics appear. The framework recommends using causal methods to identify influence paths, information-theoretic measures to track knowledge flow, and a nascent “sociology of machines” to test social hypotheses under controlled conditions. causal methods to identify influence paths, information-theoretic measures to track knowledge flow, and a nascent “sociology of machines” to test social hypotheses under controlled conditions.
Not sure where to start?Get personalized recommendations
Data Highlights
14 foundational pillars proposed for the interactionist paradigm: interactionist theory, causal inference, information theory, and sociology of machines
27 dimensions of benefits and risks identified from agent-to-agent interaction, including learning speed, distributed knowledge, and moral transfer
34 sequential learning phases highlighted in the LLM pipeline: pre-training, supervised fine-tuning, alignment with human feedback, and interactive in-context deployment
What This Means
Engineers building systems where multiple AI agents interact should care because group dynamics can create surprising behaviors, failure modes, or fast spread of errors. Technical leaders and product managers should use these insights to add agent-to-agent evaluation, tracking, and governance before deploying multi-agent stacks. Researchers can adopt the proposed tools to measure influence and design safer, more reliable agent collectives. AI governance
Key Figures
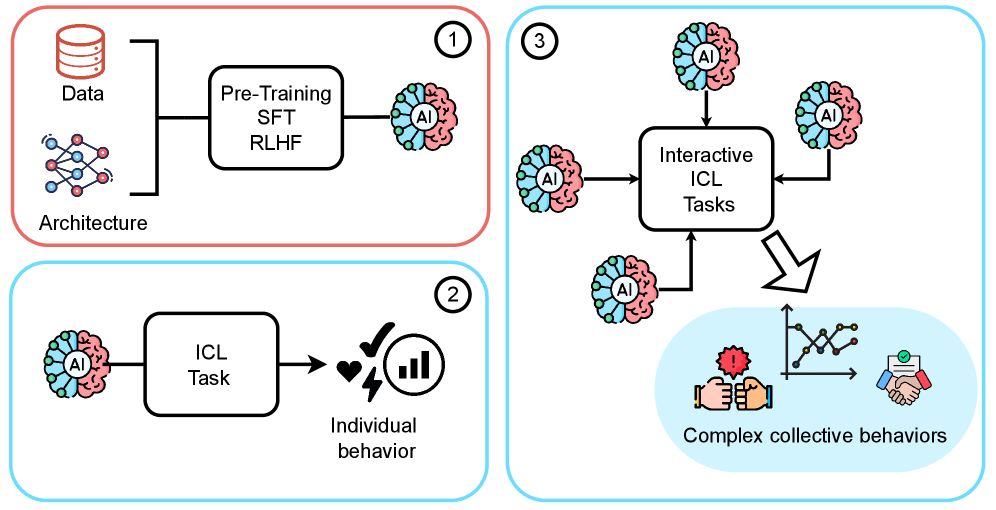
Fig 1: Figure 1 : Conceptual description of the shift from simple Gen-AI agents to a collective of Gen-AI agents . (1) On the top left, we visualize an initial phase in which an agent learns via pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). Then, two different in-context experiences are represented: (2) on the bottom left, the agent is employed in in-context learning (ICL) to solve a given task, which leads to individual behaviors; (3) on the right, instead, four agents trained according to (1) are involved in interactive ICL tasks. The interaction between the Gen-AI agents can lead to emergent complex collective behaviors that are the byproduct of individual and situational conditions.
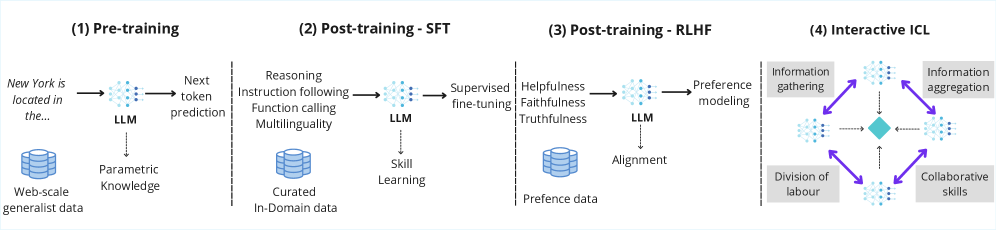
Fig 2: Figure 2 : Overview of the LLM development pipeline . The model undergoes four sequential learning phases: (1) pre-training on web-scale generalist data via next-token prediction to acquire parametric knowledge; (2) supervised fine-tuning (SFT) on curated in-domain data to learn task-specific skills such as reasoning and instruction following; (3) alignment through reinforcement learning from human feedback (RLHF), using preference data to optimize for helpfulness, faithfulness, and truthfulness; and (4) an interactive deployment phase, where agents exhibit adaptive behavior through interactive in-context learning (ICL).
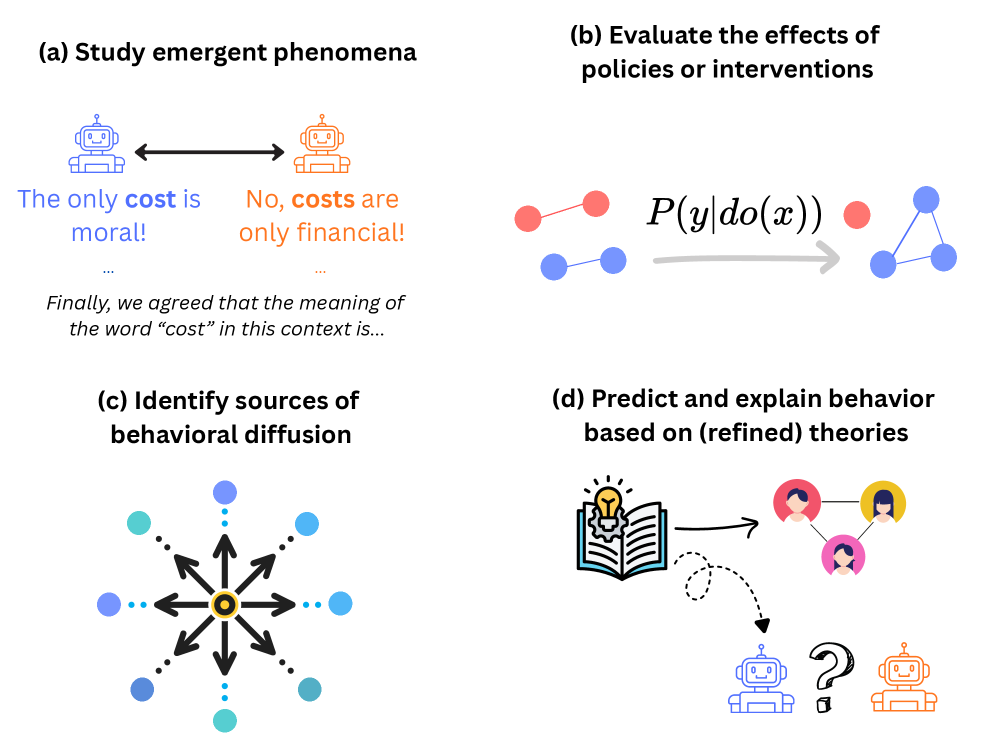
Fig 3: Figure 3 : Four areas in which our paradigm would be critical : (a) the study of emergent phenomena, exemplified by the analysis of shared meaning of concepts in debates, through the interactionist lens; (b) the evaluation policies applied to MAS via causal inference; (c) the identification of sources of behavioral diffusion in MAS via information-theoretic insights and causal inference design; (d) the development of theories via empirical scrutiny building on sociological frameworks originally designed for humans.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreKeep in Mind
The work is a conceptual perspective rather than an empirical benchmark, so practitioners will need to translate ideas into concrete tests and metrics. It focuses on agents with large pre-trained models; results may shift with different architectures or training regimes. Open questions remain about whether interaction-induced behaviors can produce lasting changes to an agent’s internal model and how to scale monitoring for large groups.
Methodology & More
Generative AI agents arrive in social settings with extensive pre-trained knowledge (their ‘personas’) and adapt transiently through in-context cues (the ‘situation’). When many such agents interact, group-level patterns — shared norms, collective biases, rapid spread of errors, or emergent cooperation — can appear that are not predictable from single-agent behavior alone. The authors argue for an interactionist paradigm that treats person and situation as joint causes, echoing long-standing debates in social science, and propose four practical research pillars: an interactionist theory, causal identification strategies to trace who influences whom, information-theoretic tools to quantify how ideas propagate, and an empirical sociology of machine collectives to test hypotheses under controlled conditions.
For practitioners, the recommendations are concrete: design agent-to-agent evaluation protocols (A2A evaluation) that separate the effect of pretrained priors from situational prompts; use causal and interference-aware experiments to identify pathways of influence and harmful diffusion; and adopt information metrics to spot consensus, polarization, or innovation flow within agent groups. Applied implications include adding continuous agent interaction logging, building an agent track record for reputation and governance, and pre-production tests that simulate social learning so emergent group behaviors can be observed and mitigated before deployment. Agent-to-Agent Evaluation Governance
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Includes Joel Z. Leibo (h-index ~42), a top researcher, raising the paper to highest credibility despite arXiv venue.