The Big Picture
Constraining how AI writers share information—by letting them critique peers but not see peers’ revisions—produces more original, higher-quality short stories; smaller models using this setup can out-perform larger single-agent models.
ON THIS PAGE
The Evidence
A blind peer review setup (agents critique initial drafts but revise independently) preserves divergent creative paths while still giving useful external feedback. On a 100-prompt science fiction benchmark, that setup produced stories with higher creativity scores and stronger lexical and semantic novelty than single-agent generation and other multi-agent schemes. The approach made a 3.2B writer model outperform larger single-agent models, showing interaction structure can substitute for scale when the goal is originality. This is consistent with the LLM-as-Judge pattern.
Not sure where to start?Get personalized recommendations
Data Highlights
1Three writer agents (N=3) were used to produce each ≈300‑word story under the LLM Review setup.
2A 3.2 billion-parameter writer (LLaMA-3.2-3B) using LLM Review outperformed larger single-agent models on creativity and novelty metrics.
3LLM Review costs about 9× the inference of single-agent generation, though using smaller models can offset that compute overhead.
What This Means
Engineers building creative AI (story generators, brainstorming assistants) can get more originality without just scaling up model size by changing how agents interact. Product and research leads evaluating multi-agent systems should consider interaction topology as a lever for creativity and cost trade-offs. Anyone tracking agent evaluation should note that feedback routing—not just more interaction—can increase novelty. See the Supervisor Pattern for tooling around interaction topology.
Key Figures
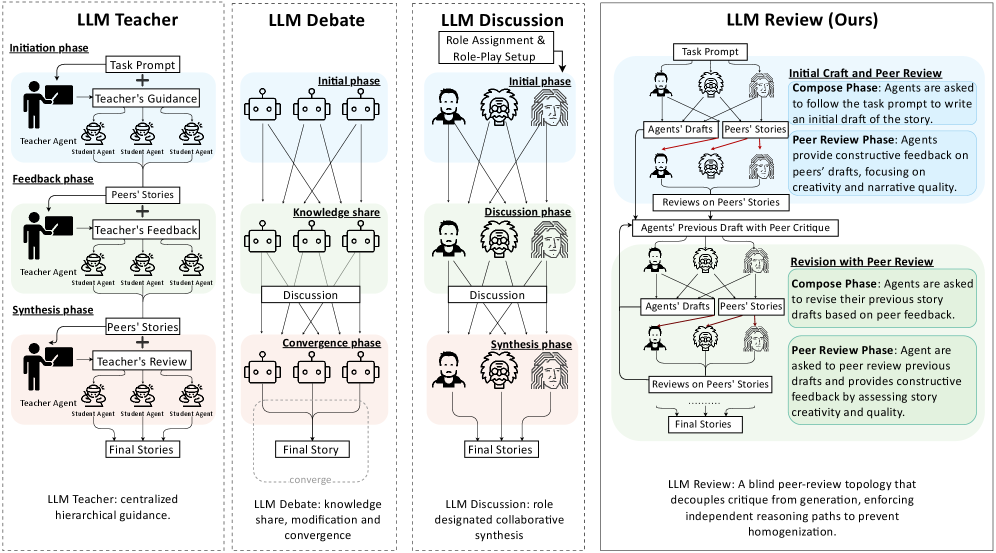
Fig 1: Figure 1: Comparison of multi-agent framework, from single-agent zero-shot writing to multi-agent frameworks. A single LLM generates a story in one pass without feedback, while LLM Teacher, LLM Debate, and LLM Discussion introduce hierarchical guidance, discussion, or role-based collaboration. LLM Review (ours) adopts a blind peer-review topology that decouples critique from generation, enabling independent revisions and reducing homogenization.
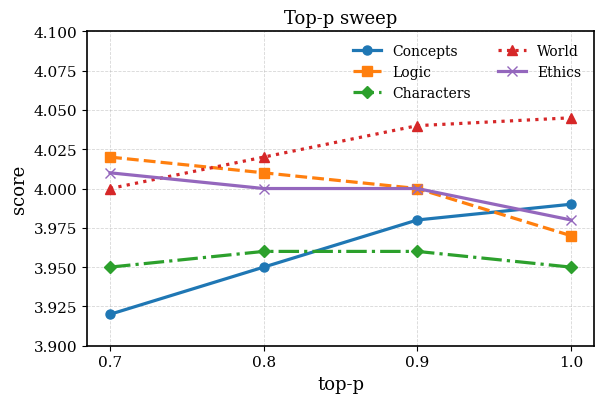
Fig 2: Figure 2: The average score of 5 LLM-as-a-judge evaluation aspects with different Top-p decoding methods.
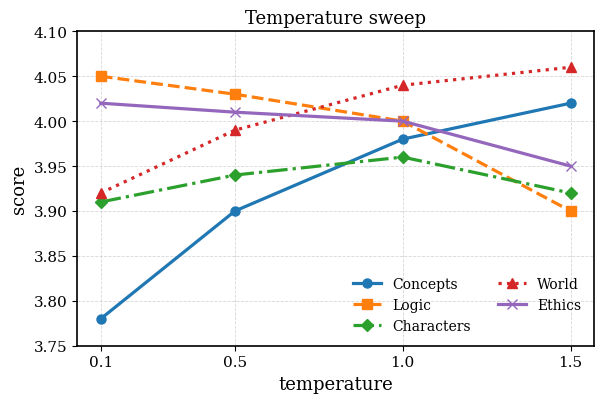
Fig 3: Figure 3: The average score of 5 LLM-as-a-judge evaluation aspects with different temperatures.
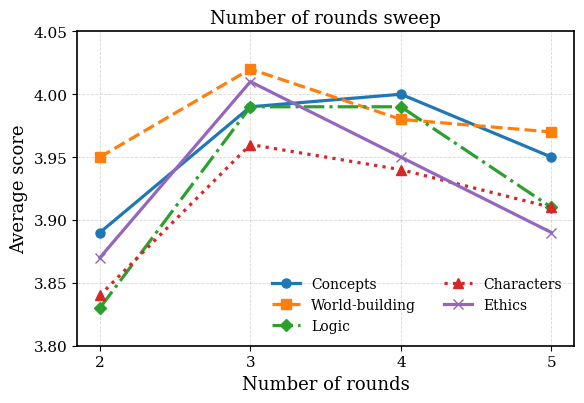
Fig 4: Figure 4: Number of execution rounds vs the average score of 5 LLM-as-a-judge evaluation aspects.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreLimitations
Results are reported on short (≈300-word) science-fiction prompts and may not generalize to poetry, long-form fiction, music, or other domains without new metrics. Novelty was measured against a fixed reference corpus (SFGram) and paired with quality judgments; divergence alone does not guarantee meaningful creativity. The human evaluation used nine student annotators, and the method raises practical costs (~9× inference) and potential for reinforcing model biases in generated narratives. Researchers might consider Guardrails to manage such risks, e.g., the Guardrails Pattern.
Methodology & More
LLM Review is a multi-agent framework that borrows the idea of double-blind academic review: each agent writes an initial draft, peers give targeted critiques of those drafts, and then each agent revises its own draft without seeing peers’ revisions. That information asymmetry preserves independent creative trajectories while allowing writers to benefit from outside critique. The team created SciFi-100, a 100-prompt science fiction dataset, and evaluated outputs with a combined toolbox: LLM-as-judge ratings across five creativity-aware dimensions, human annotation, and rule-based novelty metrics measuring lexical and semantic divergence from a reference corpus (SFGram). Across experiments using a 3.2B writer model [Foundation Model], LLM Review produced the strongest signals for creativity and novelty compared with single-agent generation and other multi-agent patterns (discussion, debate, teacher-style guidance) [Consensus-Based Decision Pattern]. The method reduced homogenization between agents and lowered score variance, meaning more robust creative quality. Key trade-offs: inference cost is about 9× higher than single-pass generation, but using smaller models in the LLM Review pipeline can be more compute-efficient than scaling a single model. The takeaway for builders is practical: redesigning how agents share feedback can be a cheaper, effective path to originality than simply increasing model size, though domain, cost, and evaluation choices matter.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors listed with Harvard University affiliation (top venue/institution) which increases credibility despite low individual h-indices.