The Big Picture
Externalizing the agent’s memory into files and keeping the reasoning context tiny makes AI agents far more stable over very long tasks — a 20‑billion‑parameter open model matched larger proprietary systems on a complex research benchmark.
ON THIS PAGE
The Evidence
Keeping long-term state in a structured workspace (files) and reconstructing a small, fixed reasoning context at each step prevents context overload and instability. A two-level hierarchy — high-level planners and low-level executors — plus an external document processor, keeps execution coherent across many steps. On multi-step research tests and a literature review of up to 80 papers, the file-based design completed long runs reliably while baseline agents degraded as their prompts grew.
Not sure where to start?Get personalized recommendations
Data Highlights
1A 20B-parameter open model using the file-centric design matched or exceeded larger proprietary agents on the DeepResearch benchmark.
2A single literature-review run processed as many as 80 papers and sustained reliable behavior across hundreds of execution steps.
3The agent keeps a tiny working buffer (example: 10 recent actions) and reconstructs context from the on-disk workspace, so context size stays fixed regardless of task length.
What This Means
Engineers building long-running autonomous agents — because this design reduces brittle failures caused by ever-growing prompt history and makes debugging easier via tangible files. Product leaders and platform owners — because smaller, cheaper models can reach competitive performance and are easier to audit and monitor. Researchers studying agent reliability — because explicit state separation offers a practical path to long-horizon stability.
Key Figures
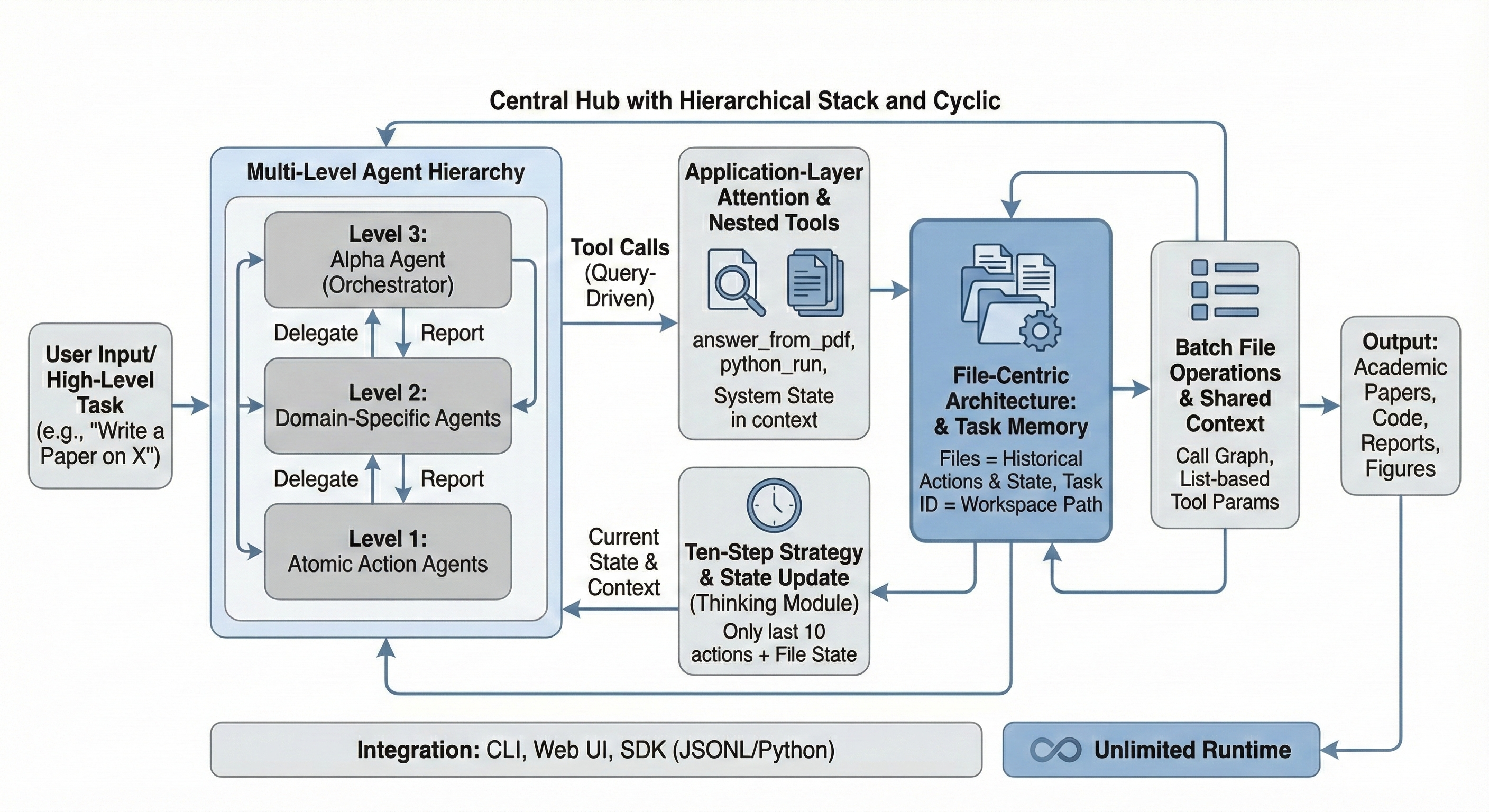
Fig 1: Figure 1: The InfiAgent Framework. InfiAgent implements a hierarchical execution stack over a file-centric persistent state. Files serve as the authoritative task memory, while an external attention mechanism processes heavy documents outside the bounded reasoning context. Periodic state consolidation refreshes the agent’s context from the workspace snapshot.
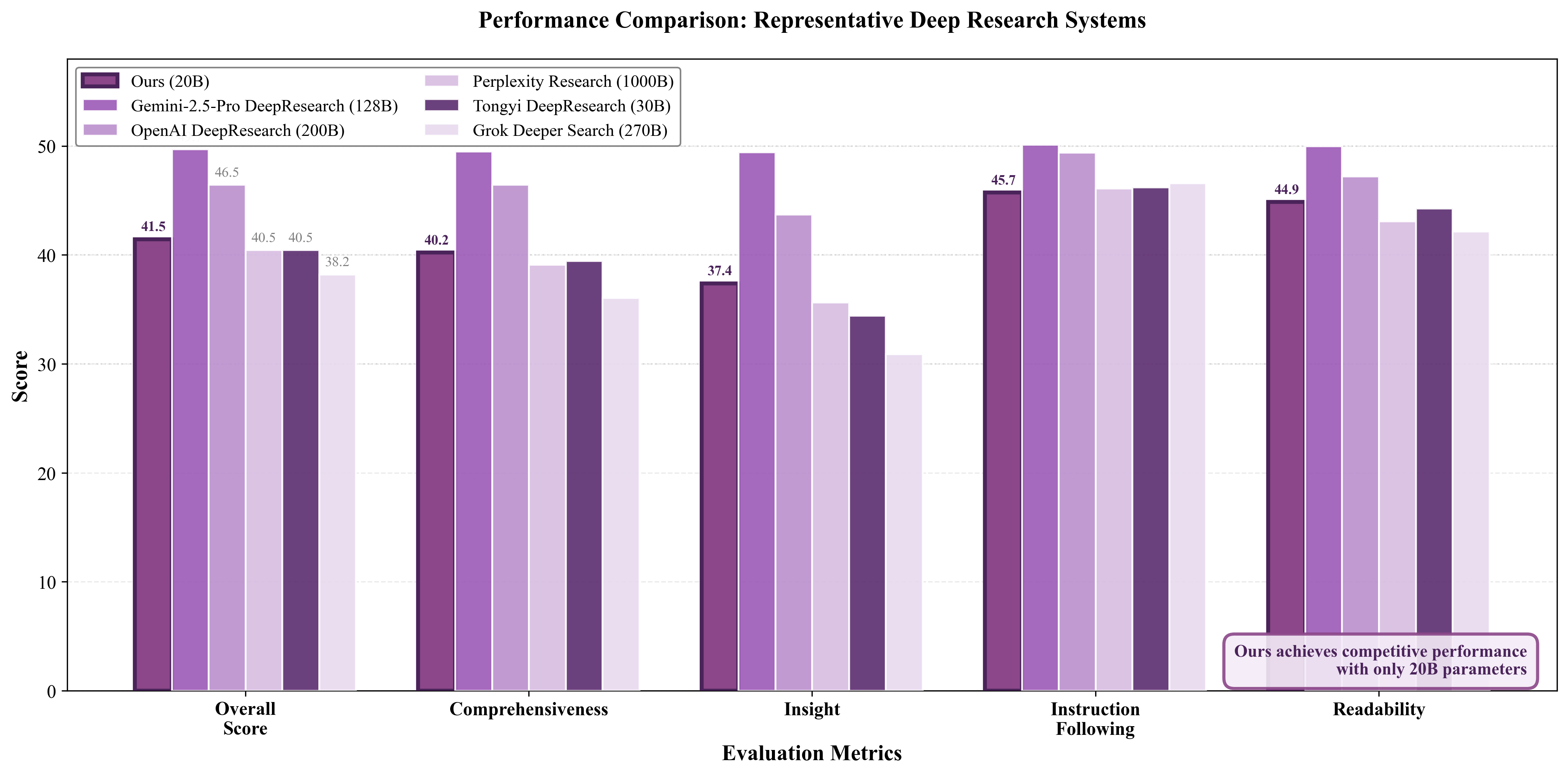
Fig 2: Figure 2: Component-wise comparison on DeepResearch. Scores are broken down by evaluation dimension. InfiAgent shows strong performance on instruction following and readability, which are closely related to structured state management and output control.

Fig 3: Figure 3: Performance vs. model size on DeepResearch. InfiAgent (20B) achieves competitive performance relative to larger proprietary agents evaluated on the same benchmark, suggesting an improved efficiency–performance trade-off.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Externalizing state does not stop the model from producing incorrect or fabricated results; if bad outputs are written to disk they can persist and mislead later steps. The hierarchical, serial execution model increases end-to-end latency and currently prevents parallel speedups for tasks that could run concurrently. Context drift is still a concern, and effective validation, human oversight, and mechanisms to detect or correct corrupted files are still required for high-stakes use cases.
Methodology & More
InfiAgent separates persistent task memory from the immediate reasoning context by storing plans, outputs, and artifacts in a structured workspace on disk. At each decision step the agent builds a bounded reasoning context from a fixed-size buffer of recent actions plus a snapshot of the workspace, so the prompt the model sees never grows unbounded. A hierarchical stack routes abstract planning to higher-level agents and concrete actions to lower-level executors, while an external attention process handles heavy document processing and only injects distilled results back into the workspace.
Evaluations focused on long-horizon robustness rather than short-run peak performance. Using the same 20‑billion‑parameter model across conditions, the file-centric agent matched or beat larger proprietary baselines on the DeepResearch benchmark and completed a literature review over as many as 80 papers across hundreds of steps without the failure modes seen in context-centric agents. The approach trades off some latency and parallelism for consistency and easier inspection: files are auditable, rollbacks are possible, and state is explicit, but bad artifacts can still propagate and the system currently runs steps serially. Overall, the framework provides a practical route to more reliable, auditable autonomous agents that can handle truly long tasks without prompt bloat. long-horizon robustness
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Authors show low h-index and no strong affiliation signals; arXiv preprint with no citations.