The Big Picture
Drive (DRIVE) is a simple, local token-exchange rule that keeps self-interested agents cooperating without retuning—even when reward magnitudes shift or scale.
ON THIS PAGE
The Evidence
A reciprocal exchange of reward differences lets neighbors penalize consistent exploiters and reward consistent cooperators, so cooperation becomes the individually rational choice. The mechanism provably flips the temptation and sucker payoffs in two-player Prisoner’s Dilemma style games, and is invariant to per-epoch reward shifts and uniform scaling. In experiments on multiple sequential social dilemmas (iterated Prisoner’s Dilemma, Coin, Harvest), DRIVE matches or outperforms state-of-the-art peer-incentive methods while requiring no hyperparameter retuning. Consensus-Based Decision Pattern
Data Highlights
1All experiments used 20 independent runs over 4,000 epochs (10 episodes per epoch) and report 95% confidence intervals.
2In the Coin domains (2 and 4 agents) DRIVE achieved the top 'own coin' rates among baselines; in the larger Harvest-12 task DRIVE tied or closely matched the best performing peer-incentive method.
3DRIVE is provably invariant to affine reward changes (per-epoch shifts and scaling) in the two-agent Prisoner’s Dilemma, so incentive alignment holds as long as the game’s greed/fear inequalities remain satisfied.
What This Means
Engineers building decentralized multi-agent systems where agent rewards can drift (robotics teams, sensor-based fleets, market-based systems) should consider DRIVE because it maintains cooperation without manual retuning. Technical leaders and researchers evaluating peer-incentive mechanisms can use DRIVE as a robust baseline for agent-to-agent evaluation and trust-building under changing reward signals. AI Governance
Not sure where to start?Get personalized recommendations
Key Figures
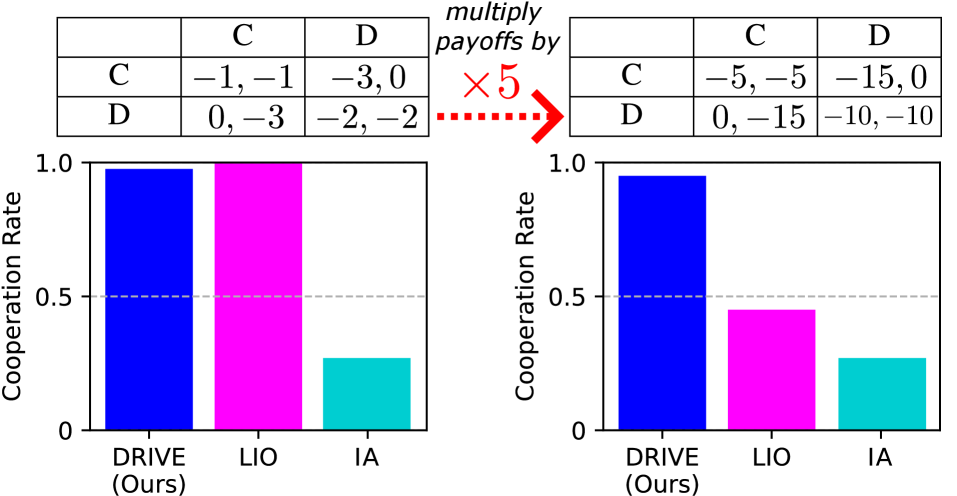
Fig 1: Figure 1. Motivating example on the reward sensitivity of PI approaches in a 2-player Prisoner’s Dilemma: IA requires careful tuning even under the original payoffs and fails to achieve cooperation in both scenarios. LIO achieves high cooperation under the original scale (left) but degenerates when the payoffs change, even though the inequalities for greed and fear (Eq. 1 ) still hold. In contrast, DRIVE maintains robust cooperation across both settings without retuning.

Fig 3: (a) DRIVE request
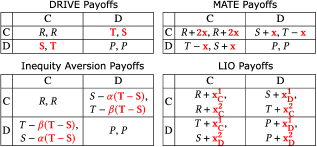
Fig 4: Figure 4. Modified PD payoff matrices of different PI methods with payoff modifications highlighted in red hughes2018inequity ; yang2020learning ; phanJAAMAS2024 .
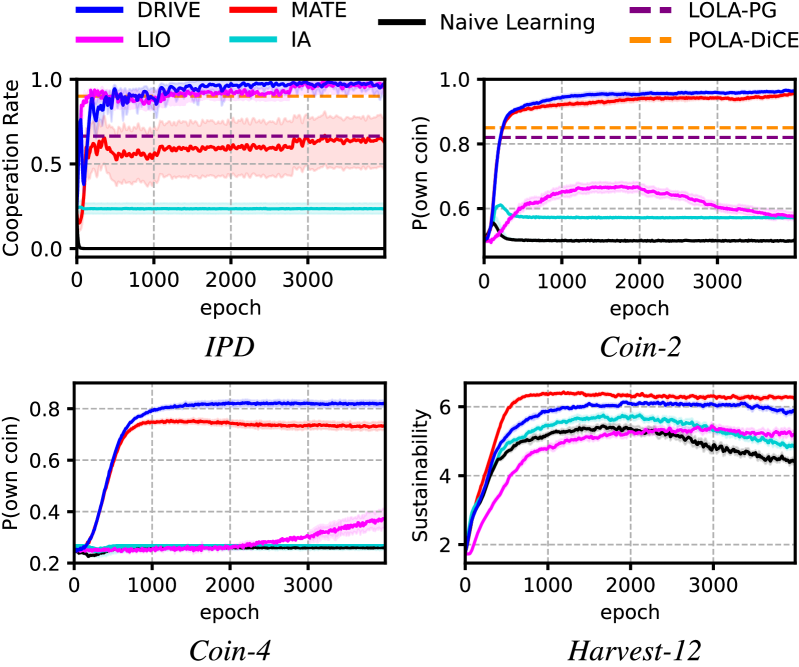
Fig 5: Figure 5. Average progress of DRIVE and other baselines in SSDs without reward change. Shaded areas show the 95% confidence interval. The results of LOLA-PG and POLA-DiCE are from foerster2018learning ; zhao2022proximal .
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
DRIVE assumes truthful, synchronous exchange of short messages between neighbors; partial or adversarial communication will degrade performance and requires additional defenses. The theoretical guarantees focus on two-agent Prisoner’s Dilemma instances and homogeneous populations; behavior in highly heterogeneous or sparse networks needs further study. DRIVE changes instantaneous payoffs to make cooperation rational but does not prove convergence of learning dynamics under all learning algorithms. Consensus
Methodology & More
DRIVE introduces a local, reciprocal token exchange where an agent with a non-negative short-term advantage broadcasts its (possibly modified) reward as a request; neighbors respond with the difference between their epoch-average reward and the request. Those differences are used to adjust both agents’ immediate rewards so that repeated unilateral defection is punished and mutual cooperation becomes the dominant outcome in Prisoner’s Dilemma–like settings. Because adjustments are based on reward differences (not absolute magnitudes), DRIVE is invariant to per-epoch shifts and uniform scaling of rewards, removing the need for hyperparameter retuning when reward signals change. Chain of Thought Pattern Guardrails Pattern Empirically, DRIVE was tested across standard sequential social dilemmas (iterated Prisoner’s Dilemma, Coin-2, Coin-4, Harvest-12) using a policy-gradient learning backbone. Across 20 seeds and 4,000 epochs DRIVE matched or outperformed state-of-the-art peer-incentive baselines (learned incentive methods, inequity aversion, token-exchange schemes), especially in domains where reward magnitudes varied. Practical caveats include the need for reliable peer messaging and the current focus on relatively well-connected interaction neighborhoods; promising next steps are adding robustness to partial compliance, extending analysis to heterogeneous populations and sparse networks, and integrating DRIVE into larger agent governance and monitoring stacks for continuous agent-to-agent evaluation and trust signals.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Contains an author (Claudia Linnhoff-Popien) with h-index 27 (>20) indicating an established researcher; arXiv preprint but author reputation raises credibility.