At a Glance
Procedural fairness — giving each agent equal influence over which option is chosen — can be learned reliably and produces policies that preserve legitimacy while balancing equality and efficiency.
ON THIS PAGE
Key Findings
Procedural fairness is formalized as allocating equal decision share to each agent’s favorite actions and scored by how well a policy can realize those shares. Algorithms were developed that learn procedurally fair policies with provable guarantees: they recover each agent’s favorite set, achieve sublinear learning regret, and can be solved via convex optimization. Procedurally fair policies guarantee each agent at least 1/N of their maximum decision share (and expected utility) and, in experiments across many settings, produced stable, balanced fairness outcomes compared with outcome-only methods. consensus-based decision pattern
Avoid common pitfallsLearn what failures to watch for
By the Numbers
17,776 distinct bandit settings evaluated (N,K up to 10); the procedural-fair algorithm achieved perfect scores on the procedural-fairness metric across the offline sweep.
2The method guarantees each agent at least 1/N of their maximum decision share and at least 1/N of their maximum achievable utility in expectation.
3Learning experiments included a 100,000-step run on a real preference dataset (γ=0.7); the algorithm converged to a procedurally fair policy with low variance; the full factorial sweep completed in ≈10 minutes on an M2 Pro.
What This Means
Engineers building coordinated AI agents and product leaders responsible for agent governance should care when legitimacy and perceived fairness matter as much as aggregate performance. Researchers studying fairness, multi-agent evaluation, or agent-to-agent trust can use the formal definition and algorithms as a new axis for trade-off analysis. AI Governance
Key Figures
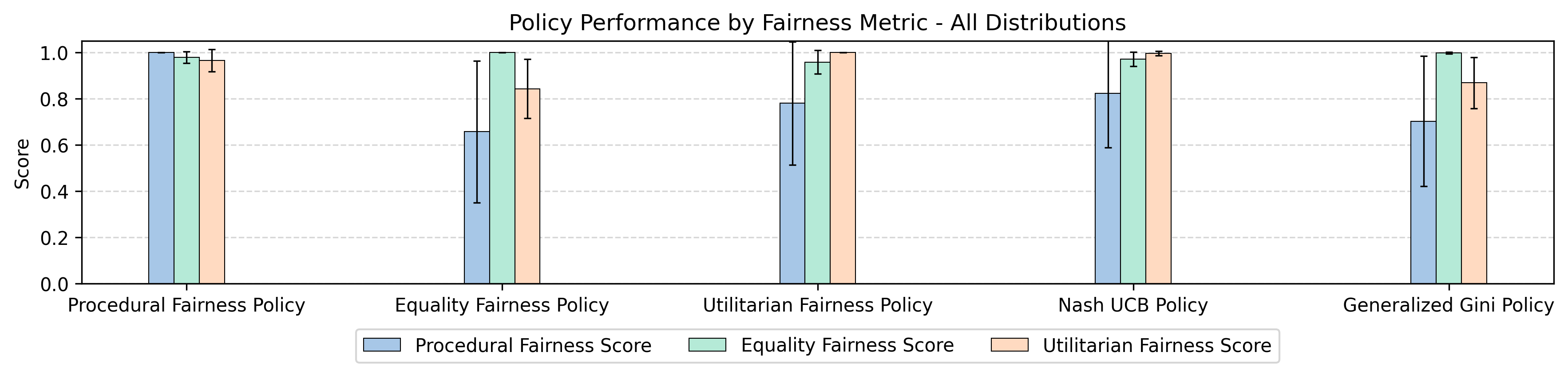
Fig 1: Figure 1 : Average fairness metrics per policy type. Each column refers to a specific policy maximizing a certain fairness notion, such as procedural, equality, or utilitarian fairness, maximizing utility-based Nash social welfare, or the Generalized Gini Index. Each bar represents a score for a fairness type, such as procedural, equality, or utilitarian fairness, and the error bars represent one standard deviation from the mean.
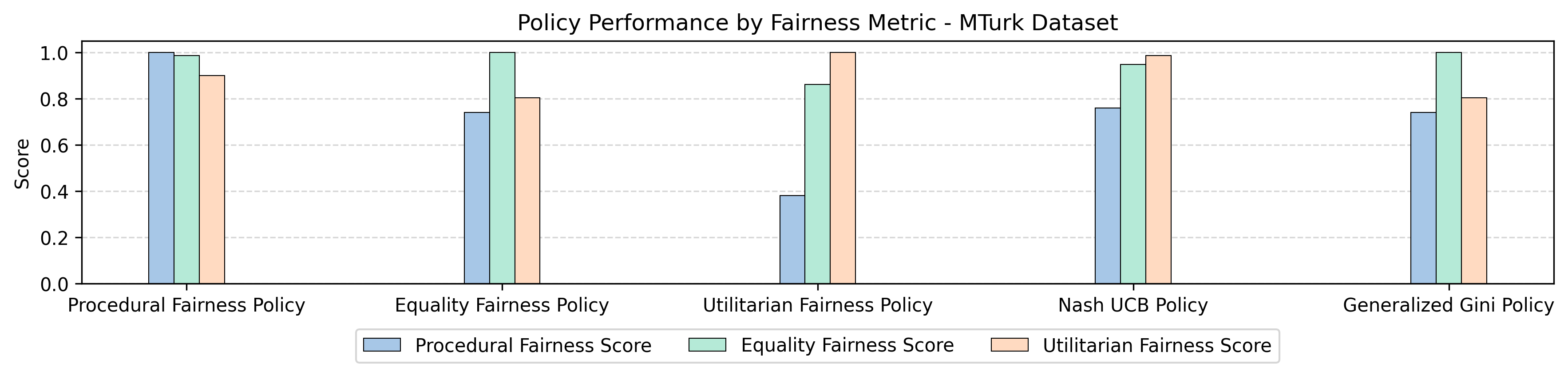
Fig 2: Figure 2 : Shows each fairness notion’s optimal policy scored on the three metrics. Each bar indicates each fairness metric, and the columns indicate each fairness notion or algorithm’s optimal policy. This graph has no error bars at it is the result from a single bandit instance (the dataset).
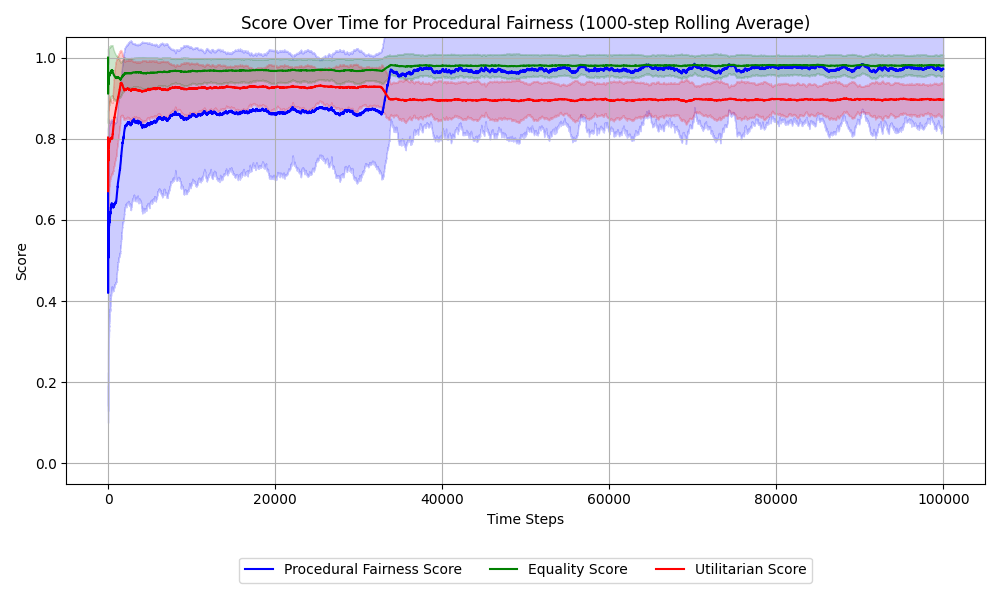
Fig 3: (a) The procedural fairness algorithm’s fairness scores over time. The shading indicates 1 standard deviation with a rolling average of 1000 steps.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Procedural fairness prioritizes equal voice and can conflict with outcome-focused goals like total utility or strict equality of payoffs, so expect trade-offs. Convergence requires a nonzero gap between favorite and non-favorite options for each agent and sufficient exploration; worst-case rates depend on that gap. Experiments are primarily on synthetic and small-scale real preference samples—behavior in large, strategic, or adversarial multi-agent deployments still needs evaluation. Guardrails Pattern
The Details
Procedural fairness reframes fairness from “what results are produced” to “who shaped the decision.” The approach defines a policy as procedurally fair if each agent contributes an equal 1/N share of decision probability and assigns that share only to their favorite arms (actions). To measure a policy’s procedural fairness, the method asks: given the policy’s distribution over arms, how much of each agent’s 1/N share can be allocated to their favorites? That allocation is computed by a convex optimization (linear constraints with a concave objective), solvable in polynomial time. Capability Attestation Pattern A learning algorithm recovers procedurally fair policies under uncertainty by first exploring all arms, then using confidence intervals (upper/lower bounds) to identify each agent’s favorite set, and enforcing equal decision shares via a constrained optimization step. Exploration is ensured by random arm selection with a decaying probability so every arm is sampled often enough for the confidence intervals to shrink. Theoretical results include impossibility proofs that procedural fairness cannot always be achieved simultaneously with outcome-based fairness notions (like utilitarian or equality fairness), a sublinear regret bound for favorite-set recovery, and the guarantee that each agent receives at least 1/N of their possible decision share and expected utility. Empirically, across 7,776 swept settings and a real preference dataset, the procedurally fair algorithm achieved perfect procedural scores and a stable balance on other fairness metrics, showing it reliably preserves voice with modest efficiency trade-offs. LLM-as-Judge
Test your agentsValidate against real scenarios
Credibility Assessment:
Affiliated with Harvard University (top institution) which raises credibility despite low individual h-indices; arXiv preprint.