At a Glance
Learn per-agent context generators that adapt during a multi-round discussion to steer AI assistants toward consistent, correct answers — yielding 20–50% accuracy gains with minimal extra runtime.
ON THIS PAGE
Key Findings
Per-agent context generators that are initialized for diverse viewpoints and then adapted each round let multiple AI instances converge on correct solutions more often. A self-adaptive balancing mechanism prevents premature agreement on the wrong answer while encouraging useful alignment. Across 9 benchmarks (reasoning, embodied agent tasks, and mobile GUI control), this approach noticeably reduces disagreement and raises final-answer accuracy compared to prior multi-agent setups. The learned context generators also transfer to different model families and sizes. Consensus-Based Decision Pattern
Avoid common pitfallsLearn what failures to watch for
Data Highlights
120%–50% relative performance improvement across 9 benchmarks, with the largest gains on complex mobile GUI control tasks
2At most 10% additional runtime overhead needed to achieve over 20% performance improvement
3Consistent gains across model sizes (from ~7B up to ~72B parameters) and across different LLM families
What This Means
Engineers building systems that combine multiple AI assistants will get more reliable outputs and fewer conflicting answers by using per-agent, evolving contexts. Technical leads evaluating multi-agent orchestration can use this to improve consensus and trust signals in production pipelines. Researchers can adopt the context-generator idea to study coordination and transfer across model types. Human-in-the-Loop Pattern
Key Figures
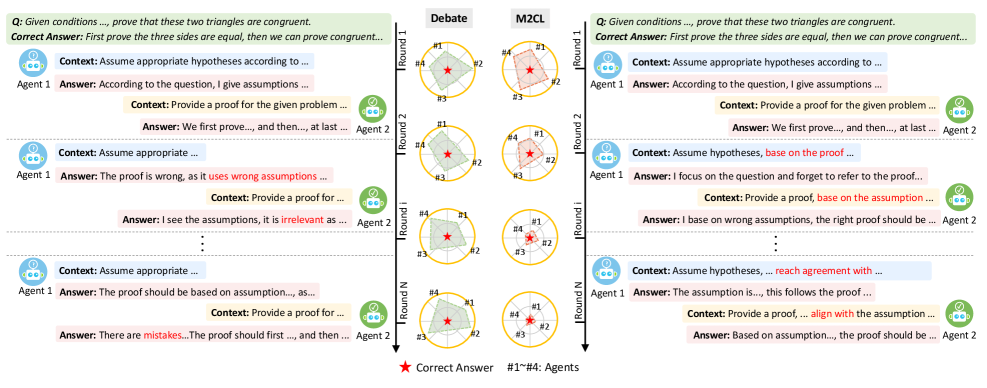
Fig 1: Figure 1: An illustration of context misalignment of an existing method ( Debate Du et al. ( 2023 ) ) on a multi-step proof task. Pre-assigned context instructions (in the blue and yellow boxes of the left part) provide insufficient guidance on information fusion, leading to conflict in reasoning.
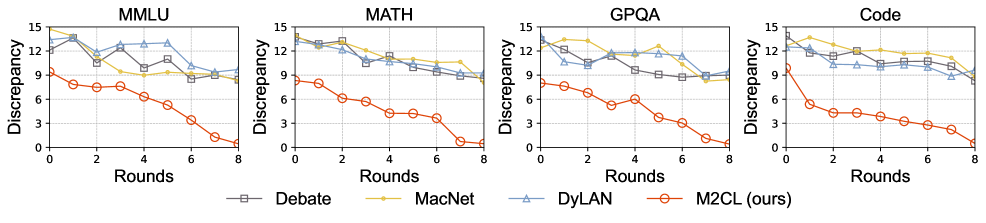
Fig 2: Figure 2: The discrepancy between the answers of participating LLM instances. The discrepancy is characterized by the maximum distance between participating LLMs’ output embeddings.
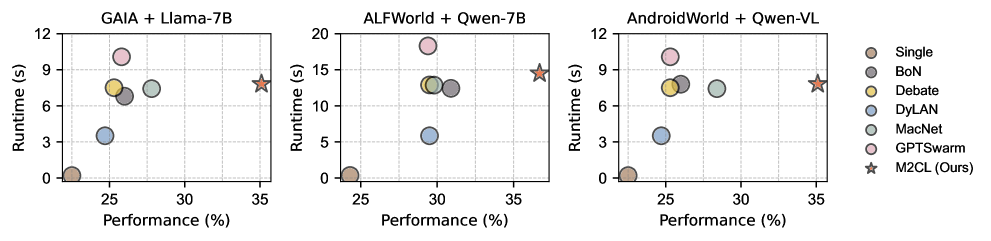
Fig 3: Figure 3: Performance versus runtime under different settings. Circles closer to the lower-left corner indicate higher efficiency.
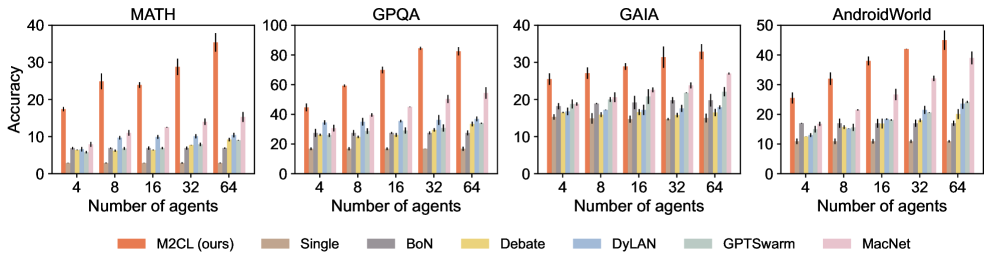
Fig 4: Figure 4: Performance of varying the numbers of LLMs. Uncertainty intervals depict standard deviation over three seeds.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Approach still relies on running multiple large models, so compute and cost can be significant compared with single-model solutions. Diversity is mainly achieved by using multiple agents rather than teaching one model many roles, which may be inefficient for constrained deployments. Risk of amplifying bias or shared errors remains if initialization or feedback channels are not carefully monitored for safety-critical domains. Consider applying Guardrails Pattern to mitigate risks.
The Details
M2CL trains a small context generator for each AI assistant so that each agent receives a tailored instruction that evolves round-by-round during a multi-agent discussion. Initialization picks diverse starting instructions by selecting near-orthogonal contexts in a learned latent space, ensuring agents start with complementary viewpoints. During discussion, each generator updates its agent’s instruction by organizing recent replies and applying a self-adaptive balance between encouraging alignment and avoiding convergence on majority noise.
A theoretical analysis frames the goal as minimizing representational distance between agent activations and the correct activation, which motivates both diverse initialization and controlled evolution. Empirically, M2CL outperforms single-agent baselines and several multi-agent methods on 9 datasets spanning academic reasoning, embodied-agent tasks, and mobile GUI control — reporting 20–50% relative gains and improved agreement among agents. The method adds modest runtime (≤10%) and the learned generators transfer across different model architectures and sizes, making it practical for teams that can afford multi-agent setups. Remaining caveats include higher compute needs and the potential for bias amplification in sensitive applications. Planning Pattern Event-Driven Agent Pattern
Need expert guidance?We can help implement this
Credibility Assessment:
Authors have low-to-modest h-indices (mostly <10) and no strong venue or affiliation signals.