In Brief
A two-agent cascade lets cheap, fast detectors handle routine camera frames and only sends hard cases to expensive language-capable vision models, cutting heavy checks threefold while keeping human-readable explanations.
ON THIS PAGE
Key Findings
A dual-agent design (one that reacts to alarms and one that continuously checks cameras) coordinates a three-stage cascade: a fast object detector, a reconstruction-based anomaly scorer, and a vision–language stage that produces text explanations. Most frames exit early after the fast stages, dramatically reducing expensive language-model calls while preserving semantic labels for ambiguous events. Free-text outputs are normalized into stable categories using an embedding classifier that can abstain when uncertain, improving label consistency for downstream operators. The approach proved practical on a transport-hub style deployment and a large benchmark, showing gains in efficiency and interpretability. The vision–language stage that produces text explanations is part of this cascade.
Data Highlights
1High reconstruction fidelity: Peak PSNR = 38.3 dB and SSIM = 0.965 (strong frame reconstruction quality).
2Efficiency gain: Cascading design achieved a threefold reduction in end-to-end latency compared to running the vision–language stage on every frame.
3Operational scale: System processed 329,000 frames and flagged 6,990 anomalous events during evaluation on UCF‑Crime.
Implications
Engineers building real-time camera monitoring and multi-agent systems will get a practical template for saving compute and getting readable alerts. Technical leaders evaluating surveillance stacks can use the cascade to balance cost, speed, and explainability when deploying language-capable vision models. Researchers working on agent coordination or model distillation can reuse the dual-agent orchestration and early-exit gating as a baseline. Supervisor Pattern can provide a broader governance context for these workflows.
Explore evaluation patternsSee how to apply these findings
Key Figures
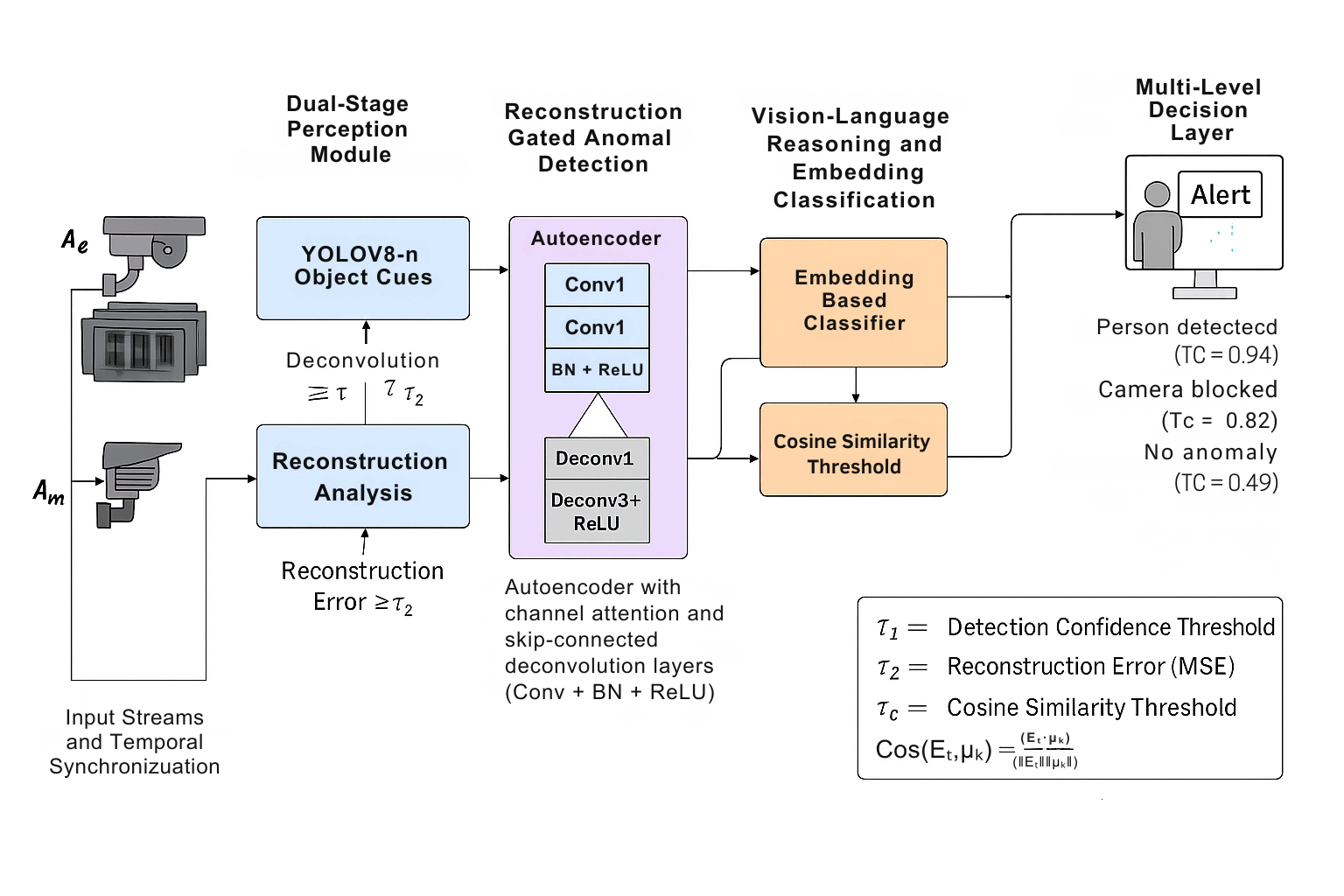
Fig 1: Figure 1: Proposed Methodology.
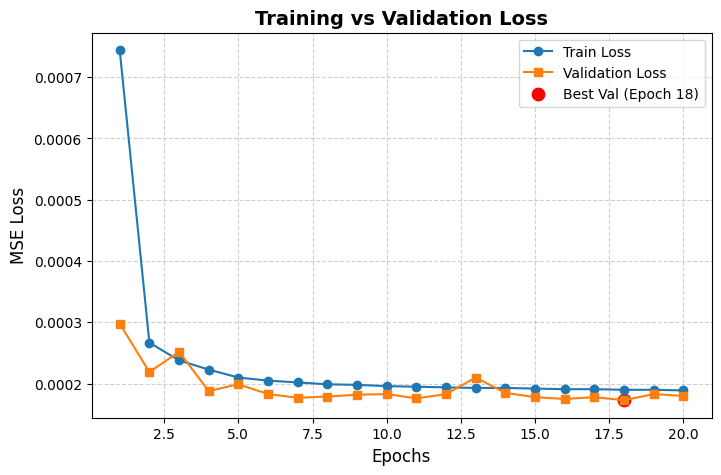
Fig 2: Figure 2: Training and validation MSE loss curves across 20 epochs. Loss converges within the first 10 epochs and stabilizes near 1.7 × 10 − 4 1.7\times 10^{-4} .
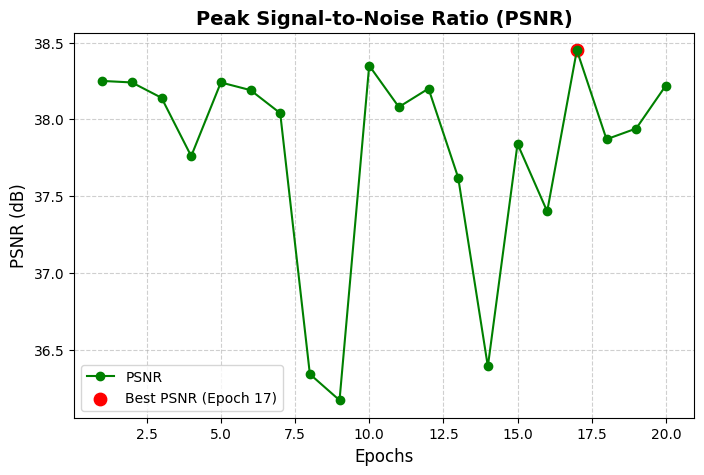
Fig 3: Figure 3: PSNR across training epochs. Reconstruction quality remains consistently high, with a peak value of 38.45 dB at epoch 17.
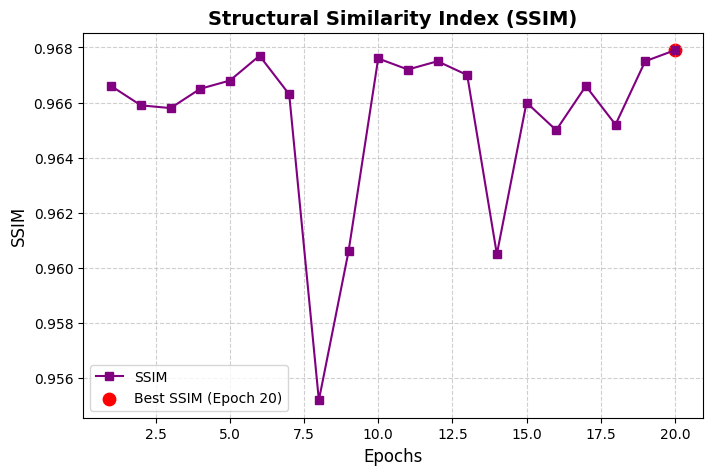
Fig 4: Figure 4: SSIM across training epochs. Structural fidelity remains consistently high, with the best SSIM (0.968) achieved at epoch 20.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
The language-capable vision stage still dominates latency (reported at about 6–12 seconds per heavy call), so improvements require model distillation, batching, or sequence-level modeling. The reconstruction-based gate is sensitive to lighting and camera noise and can produce false positives under severe illumination changes. Evaluation focused on UCF‑Crime and an internal transport-hub case; cross-dataset robustness and direct comparisons with leading baselines remain needed for wider claims. Guardrails Pattern can guide safe deployment and monitoring of these multi-agent pipelines.
Methodology & More
A cascading multi-agent pipeline pairs an event-driven agent (which responds to asynchronous alarms) with a cyclical monitoring agent (which periodically probes camera health). Frames flow through a fast object detector first; frames that deviate from learned normal patterns are then scored by a convolutional autoencoder. Only ambiguous or semantically rich cases are escalated to a vision–language model (a model that links visual content to text) for natural-language descriptions. Those free-text outputs are converted into structured anomaly labels via an embedding-based classifier that can abstain when confidence is low, yielding consistent labels for operators. On the UCF‑Crime benchmark and a transport-hub case study the cascade kept most frames in the cheap early stages, delivering a threefold latency cut versus always-running the language stage, while preserving interpretability. Chain of Thought Pattern Reconstruction quality was high (PSNR ~38.3 dB, SSIM ~0.965) and the system processed 329k frames, detecting 6,990 events. Remaining gaps include the long per-call latency of the vision–language model (6–12 s), sensitivity of reconstruction scores to lighting, and the need for cross-dataset benchmarks and head-to-head comparisons with state-of-the-art baselines. Next steps that matter in practice are adding temporal sequence models, distilling or batching the language stage, and extending the multi-agent stack with privacy-preserving and failure-monitoring features to support trustworthy deployments.
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Affiliated with Università degli Studi dell'Aquila and an author (Giovanni De Gasperis) with moderate h-index (~14), providing some credibility.