At a Glance
Two conversational agents can steer a frozen diffusion language model to produce schema-correct, diverse JSON without fine-tuning, reaching 79% task success and lower field overlap than strong baselines.
ON THIS PAGE
The Evidence
A pair of language-model agents — one that proposes prompt edits and one that judges outputs — use plain-language feedback to guide a diffusion-based text generator toward strict JSON schemas. The diffusion model itself stays frozen (no fine-tuning); only the prompt optimizer is trained using a reinforcement-style loop that interprets verbal feedback as its learning signal. Across four structured benchmarks, this setup boosted task success and reduced field overlap compared with both diffusion and autoregressive baselines, while producing more diverse and novel outputs. The method runs on consumer-grade hardware and supports both local open models and API-based models, making it practical to reproduce. Supervisor Pattern.
Not sure where to start?Get personalized recommendations
By the Numbers
1Achieved a Task Success Rate of 0.79 (79%) across the structured JSON generation suite, the highest among compared methods.
2Lowered Field Overlap to 0.29 (29%), indicating better adherence to schema fields and less repeated or overlapping content.
3Reproducible on a consumer workstation (12-core AMD Ryzen 9 7900X, 32 GB RAM, NVIDIA RTX 4080 SUPER with 16 GB VRAM) and compatible with local 8–9B models or cloud APIs.
Why It Matters
Engineers building synthetic-data pipelines or APIs that must output strict JSON or nested records will benefit from a method that improves format correctness without retraining large models. Technical leads deciding between retraining models or adding validation scaffolding can use this to get higher-quality, more diverse outputs while keeping base models unchanged. Researchers interested in agent-based model control can use the approach as a practical, interpretable alternative to reward engineering. agent-based model control.
Key Figures
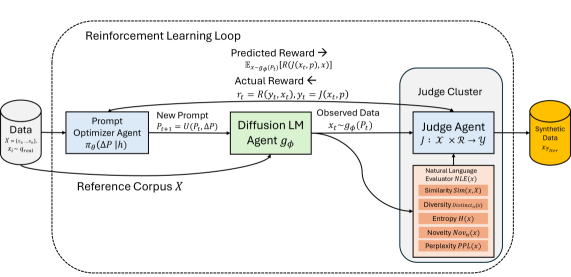
Fig 1: Figure 1. Agents of Diffusion: Overview of the multi-agent training framework.
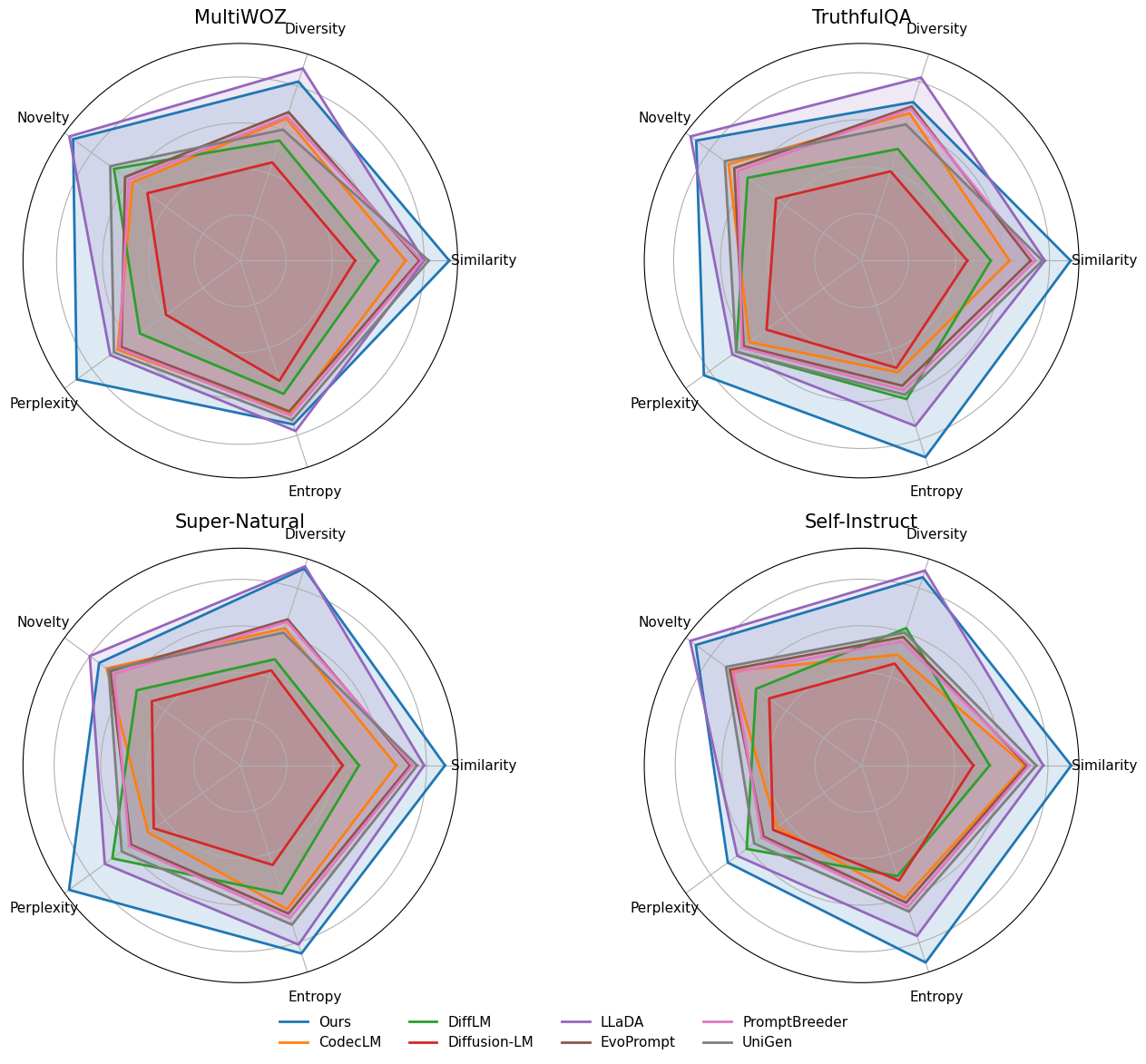
Fig 2: Figure 2. Comparison of normalized metrics across datasets.
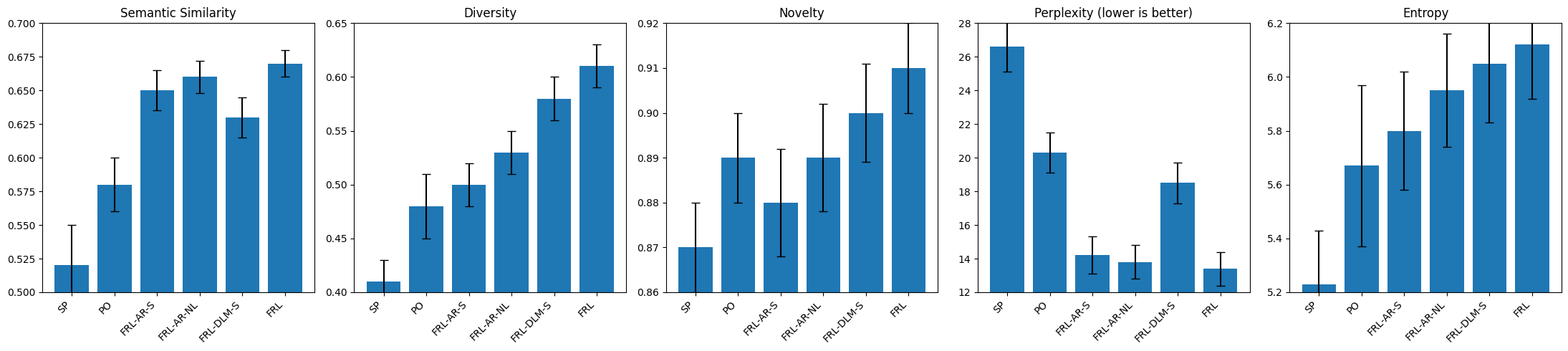
Fig 3: Figure 3. Ablation of agents, averaged across datasets and Optimizer–Judge pairs. SP = Static Prompt, PO = Prompt Optimizer, FRL–AR–S = Autoregressive generator with scalar rewards, FRL–AR–NL = Autoregressive generator with natural language feedback, FRL–DLM–S = Diffusion generator with scalar rewards, FRL = Diffusion generator with natural language feedback.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreYes, But...
Results are reported for nested JSON generation only; behavior on tabular data, code, or other structured formats was not tested. The approach depends on the quality of the judge and prompt-optimizer agents — weak judges could misdirect the optimizer. Using API-based models for the agents can incur usage cost and latency, and generalization to much larger or different data distributions remains unproven. LLM-as-Judge.
Full Analysis
AoD (Agents of Diffusion) pairs a frozen diffusion language generator with two conversational agents: a prompt optimizer that suggests natural-language edits to the generation prompt, and a judge that reads a candidate output and returns verbal feedback and scores against a schema. A scorer translates that feedback into scalar and subrewards (things like semantic fit, novelty, or field-level correctness). The optimizer is trained with a reinforcement-style loop that treats the judge’s natural-language critique as the learning signal; the diffusion model’s weights remain unchanged, so control is achieved without fine-tuning the generator.
In experiments on four JSON-focused benchmarks requiring nested fields and strict schemas, the multi-agent loop increased task success to 79% and cut field overlap to 29% versus diffusion and autoregressive baselines, while also boosting measures of diversity and novelty. The system runs on readily available consumer hardware and supports both open-source local models and proprietary API models for the agents, making it easy to reproduce. The approach is a practical way to combine the semantic breadth of diffusion generators with structured control delivered via conversational agent supervision, though it’s currently validated only for JSON outputs and depends on robust judge behavior for reliable performance. semantic-capability-matching-pattern guardrails-pattern.
Test your agentsValidate against real scenarios
Credibility Assessment:
Authors have low h-indices and no listed strong affiliations or venue — limited credibility.