Key Takeaway
Training a voice model to explicitly choose between its own hearing, an external transcript, or a rethink dramatically reduces harmful corrections and makes audio answers more reliable and interpretable.
ON THIS PAGE
What They Found
Naively feeding both audio and external text into a single model often makes speech recognition worse. Teaching the model a simple decision token — pick internal, pick external, or rewrite — lets it learn when to trust itself and when to accept outside help. The model reliably predicts when to use its own decoding or an external transcript, improving results on speech recognition and audio question answering. Rethinking (rewrite) helps when needed but is rare and harder to learn with limited examples, as seen in the Chain of Thought Pattern.
Data Highlights
1Naive audio-plus-text fine-tuning raised word error rate to 8.52%–9.05% on OpenASR tests, worsening performance versus baselines.
2Action distributions show 'internal' exceeds 95% in several datasets; 'internal' F1 reaches 0.94 (Libri-clean), 0.91 (SPGI), and 0.90 (Libri-other).
3'Rewrite' decisions have F1 below 0.4 across most datasets and are zero in LibriSpeech, indicating low recall for rewrite cases.
Why It Matters
Engineers building speech and audio assistants will get a practical way to reduce wrong corrections and add an explicit trust signal to decisions. Technical leads deploying multimodal agents can use the action token output for monitoring, governance, and safer fallbacks. Researchers in agent decision-making and multi-agent trust will find a concrete, trainable arbitration mechanism to evaluate and improve.
Explore evaluation patternsSee how to apply these findings
Key Figures
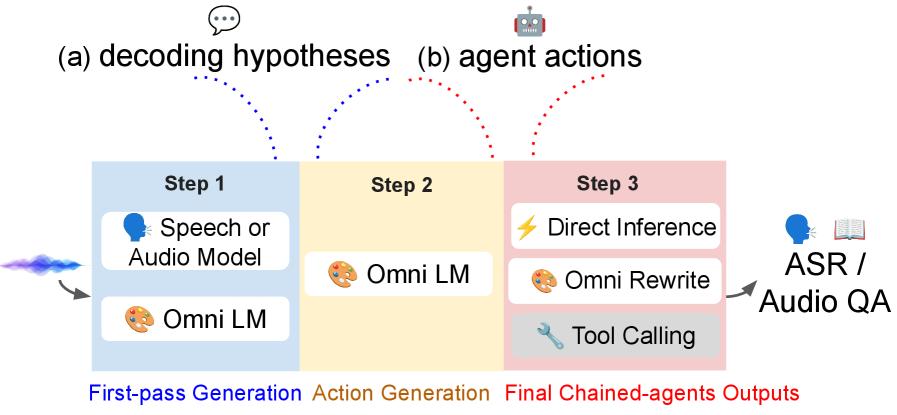
Fig 1: Figure 1: Speech-Hands acts as a dynamic orchestrator that predicts a special action token to govern its cognitive strategy for ASR and multi-domain audio reasoning.
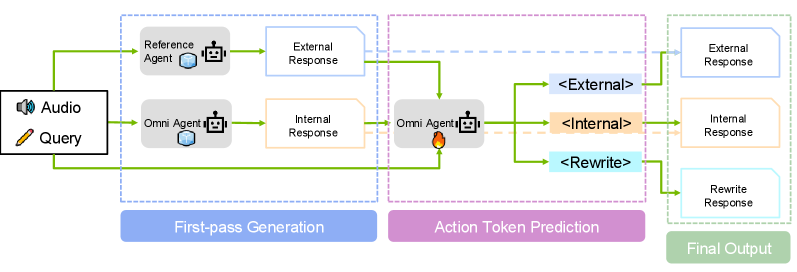
Fig 2: Figure 2: Overview of our proposed Self-Reflection Multimodal GER framework. A special token is generated at the beginning to decide whether to use audio perception (i.e., transcription hypotheses or caption) or not.
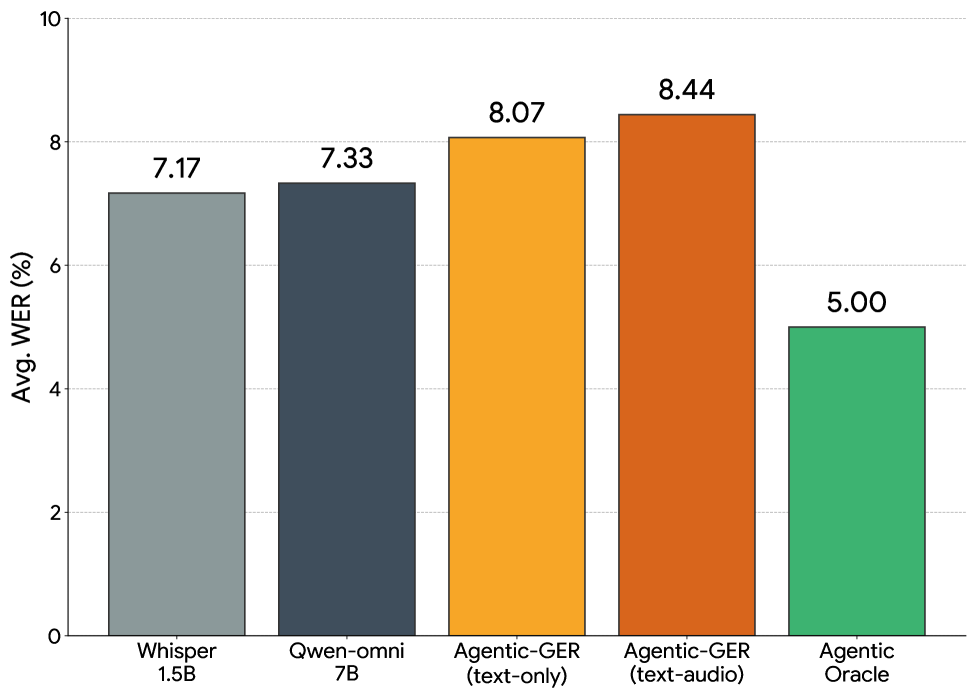
Fig 3: Figure 3: Preliminary results on the cascaded agentic Qwen-omni baseline for generative error correction (GER) with supervised fine-tuning show that both text-only and text-audio GER degrade ASR performance, where the best ASR and LLM combination achieves a low agentic output oracle of 5% WER.
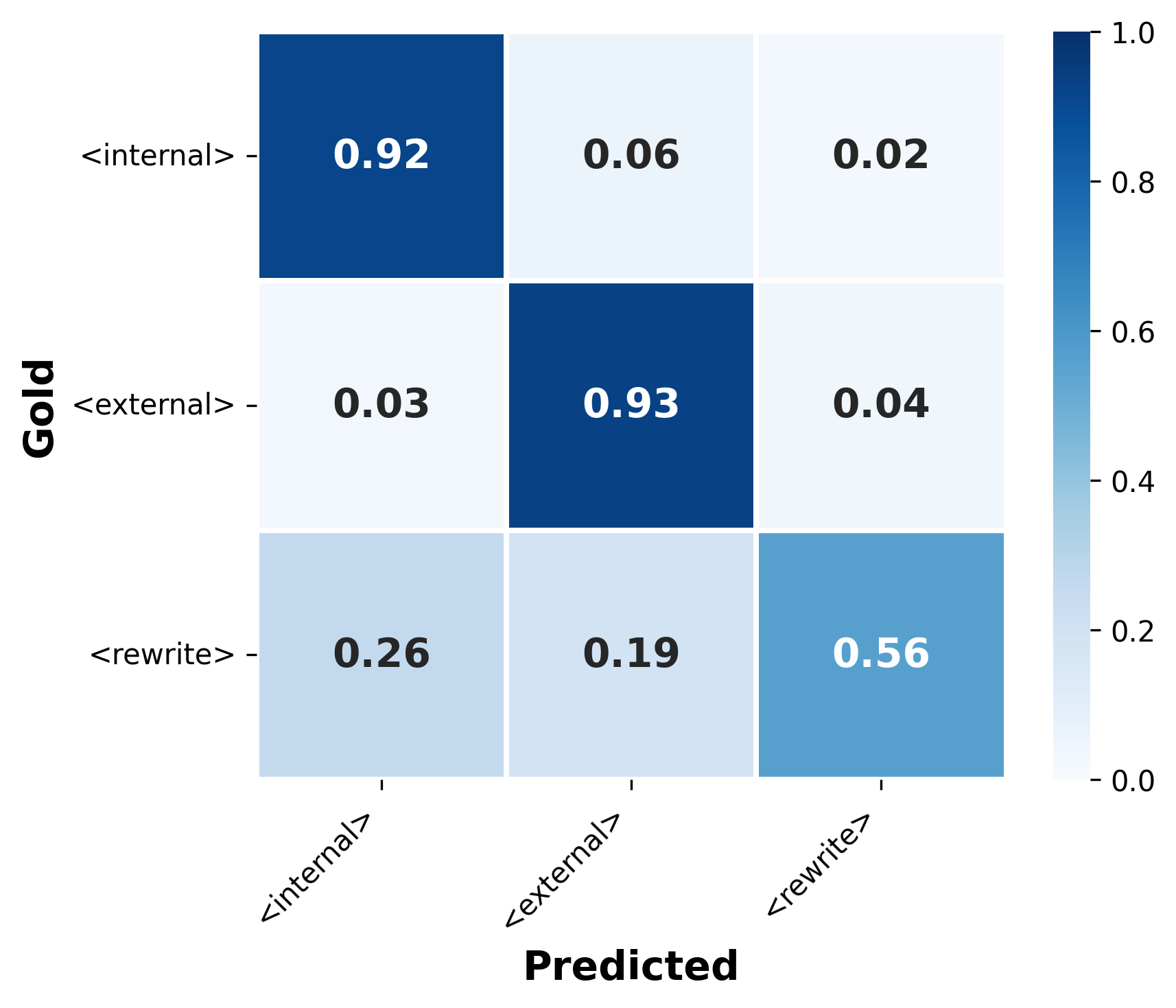
Fig 4: (a) Bio-acoustic QA
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
Action-token training is imbalanced: 'internal' dominates the data, making 'rewrite' underrepresented and hard to learn robustly. Experiments used a single large multimodal backbone and one external transcription system, so gains may vary with other models or stronger external experts. Tool-calling (invoking external utilities) was left for future work, so real-world tool integration and costs are not evaluated here.
Deep Dive
Models that blindly combine audio and external transcripts can be confused and often perform worse than individual systems. A better approach is to let the model decide how to act: produce its own transcript, accept an outside transcript, or rewrite after rethinking the audio and available suggestions. The method extends a multimodal model with three special action tokens — <internal>, <external>, <rewrite> — and trains the model using supervised labels that pick the best action per example by comparing internal, external, and corrected hypotheses against ground truth. This aligns with the action tokens approach and helps practitioners inject explicit trust into decisions. Applied across seven diverse speech datasets and a multi-domain audio question-answering benchmark, the action-token approach recovers and improves performance where naive fusion failed. The model learns to emit <internal> and <external> reliably (high F1 despite skewed supervision), giving an interpretable signal about which source it trusted. The <rewrite> action is precise but under-triggered because examples are rare; improving coverage will likely require targeted augmentation or sampling. Overall, this gives practitioners a lightweight, monitorable way to inject explicit trust and delegation decisions into multimodal voice systems, aiding reliability and multi-agent trust workflows, supported by monitorable evaluation.
Test your agentsValidate against real scenarios
Credibility Assessment:
Multiple authors with modest h-indexes and some recognizable names, but arXiv venue and no top-institution signal; overall moderate credibility.