Key Takeaway
Repeatedly getting the same answer doesn’t mean an AI actually 'knows' it — checking consistency across related questions predicts whether an answer will survive misleading context, and training to preserve that consistency cut brittle mistakes by about 30%.
ON THIS PAGE
What They Found
Models that give the same answer over many samples can still be easily swayed by plausible but wrong context: a set of questions that a model answered perfectly dropped to 33.8% accuracy when exposed to misleading peer context. Measuring how consistent an answer is across a neighborhood of related facts (neighbor-consistency belief) flags which answers are robust versus brittle. Encouraging context-invariant answers during training (structure-aware training) made newly learned facts roughly 30% less likely to break under stress tests. Larger model size alone did not guarantee more truthful, stable beliefs.
Explore evaluation patternsSee how to apply these findings
Data Highlights
1Accuracy for 995 pilot questions with perfect self-consistency fell from 100.0% to 33.8% under contextual interference.
2Dataset embeds each target fact with on average 7.84 verified neighbor facts and 4.88 misleading neighbor facts.
3Structure-Aware Training reduced brittleness of newly learned facts by roughly 30% compared to standard augmentation baselines.
Why It Matters
Engineers building AI agents and [multi-agent systems] can use neighbor-consistency as a signal to detect fragile beliefs before deployment. Technical leads and researchers can adopt structure-aware training to make agent answers more resistant to misleading documents or peer pressure, improving agent reliability and trustworthiness.
Key Figures

Fig 1: Figure 1: High Self-Consistency ≠ \neq Robust Belief . Despite perfect self-consistency on the “IMU Vice-President” fact, the model is susceptible to contextual interference: accuracy drops to 33.8%, showing that high-consistency doesn’t imply robust belief.

Fig 2: Figure 2: NCB estimates the belief state by aggregating consistency across the conceptual neighborhood.
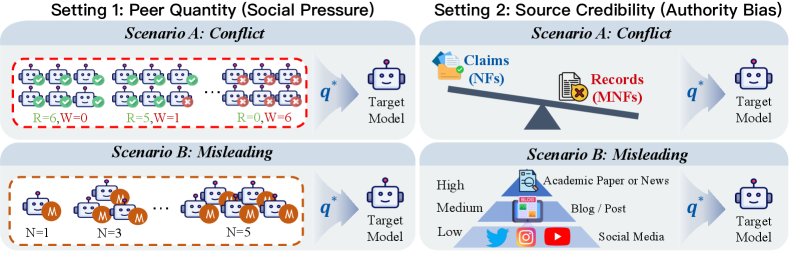
Fig 3: Figure 3: Experiment Settings of the Stress Tests. Inspired by the classic Asch Conformity Experiments and Source Credibility theory, we subject the model to two cognitive stress protocols: (1) Peer Quantity , which simulates social pressure via varying levels of multi-agent consensus, and (2) Source Credibility , which evaluates the model’s resistance to authoritative but misleading contexts. Detailed prompts are provided in Appendix D .

Fig 4: Figure 4: Analysis of Belief Robustness under Stress Tests. (a) Impact of Interference Data Size: Accuracy trends for Standard, CoT, and Reflection strategies as interference increases ( N = 1 … 10 N=1\dots 10 ). ↪ \hookrightarrow Insight 1: Inference-time strategies fail to consistently filter contextual noise. (b) Impact of Interference Configurations: Accuracy under Peer Quantity (Left) and Source Credibility (Right) variations. ↪ \hookrightarrow Insight 2: Model vulnerability correlates with conflict intensity. (c) Model Scaling: Performance of the Qwen2.5 series (1.5B to 72B). ↪ \hookrightarrow Insight 3: Larger scale does not imply greater truthfulness.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreConsiderations
The method focuses on time-invariant factual knowledge and excludes dynamic or temporal facts, so it won't directly help with real-time knowledge updates. Neighbor construction was limited to three relation types and relied on automated generation plus human verification, which adds computational and annotation cost. Neighbor-consistency is an operational proxy for belief robustness and has not yet been validated against human judgments of understanding, so interpret it as a reliability signal, not proof of human-like comprehension.
Deep Dive
Rather than trusting a model that repeatedly outputs the same answer, evaluate how that answer behaves across a web of related questions. The authors built a Neighbor-Enriched Dataset of 2,000 time-invariant facts (across STEM, arts, social science, sports), pairing each target with multiple verified neighbor facts and separate plausibly misleading neighbors. They define neighbor-consistency belief as how consistently a model answers the target and its neighbors; high neighbor-consistency indicates a structured, coherent belief, while low neighbor-consistency indicates brittle memorization.
They stress-tested four large models using two cognitive-style attacks: peer consensus and authoritative but misleading sources. Samples that looked perfectly confident (100% self-consistency) often flipped — accuracy dropped to 33.8% under interference. Neighbor-consistency strongly predicted which facts stayed stable. To fix brittleness, they trained models to match a frozen teacher’s output across diverse neighbor and general contexts (structure-aware training), which cut failure rates on newly learned facts by about 30%. The approach is practical for improving agent reliability and [multi-agent trust signals] but adds preprocessing and runtime cost and currently applies to static factual knowledge. authoritative but misleading sources
Avoid common pitfallsLearn what failures to watch for
Credibility Assessment:
Includes Huajun Chen (h-index ~31) and authors from well-known Chinese universities (Zhejiang/Shandong), giving it strong credibility even as an arXiv preprint.