Key Takeaway
DarwinTOD lets a conversational agent continuously learn from its own interactions by running many competing strategies, critiquing them, and evolving the best ones — producing steady, measurable gains without human tuning.
ON THIS PAGE
What They Found
DarwinTOD maintains a pool of dialog strategies that compete during live conversations and then get evolved offline using feedback and peer critiques. The system balances exploring new strategies and exploiting good ones with a simple selection rule, and it prunes bad strategies over time. Using this dual-loop (live + offline) approach, DarwinTOD achieves state-of-the-art results across standard task-oriented dialog benchmarks and is robust to weak or minimal initial setups. Consensus-Based Decision Pattern.
Explore evaluation patternsSee how to apply these findings
By the Numbers
1Top combine score 120.59 on MultiWOZ 2.0 using a powerful model (GPT-5.1).
2Reached 96.2% task success on MultiWOZ 2.0 (GPT-5.1).
3Overall combine improvements of about 3–6% vs prior state-of-the-art across MultiWOZ versions (e.g., +5.9% over previous best).
Why It Matters
Engineers building customer-service or assistant bots — because they can deploy a system that keeps improving without repeated human retraining. Product and platform leads evaluating continuous learning options — because DarwinTOD shows a practical way to get steady gains while controlling compute by using stronger models only in offline evolution. Researchers studying multi-agent or evolutionary systems — because the method combines agent critique with population-based evolution in a dialog setting. Supervisor Pattern
Key Figures

Fig 1: Figure 1: Motivation comparison of TOD architectures. Both pipeline and end-to-end TOD systems suffer from cascaded errors or lack experience driven improvement, while DarwinTOD enables lifelong self evolution via a dual-loop architecture to achieve autonomous improvement.

Fig 2: Figure 2: DarwinTOD’s dual-loop algorithm framework. The online phase executes dialogs via multi-agent collaboration (DST/DP/NLG/UserSim) with peer critique, retrieving strategies from ESB through Boltzmann selection and logging interactions to SSM. The offline phase triggers evolutionary operations (Generate/Mutate/Consolidate/Prune) based on SSM feedback to update ESB, forming a closed loop for autonomous strategy refinement.
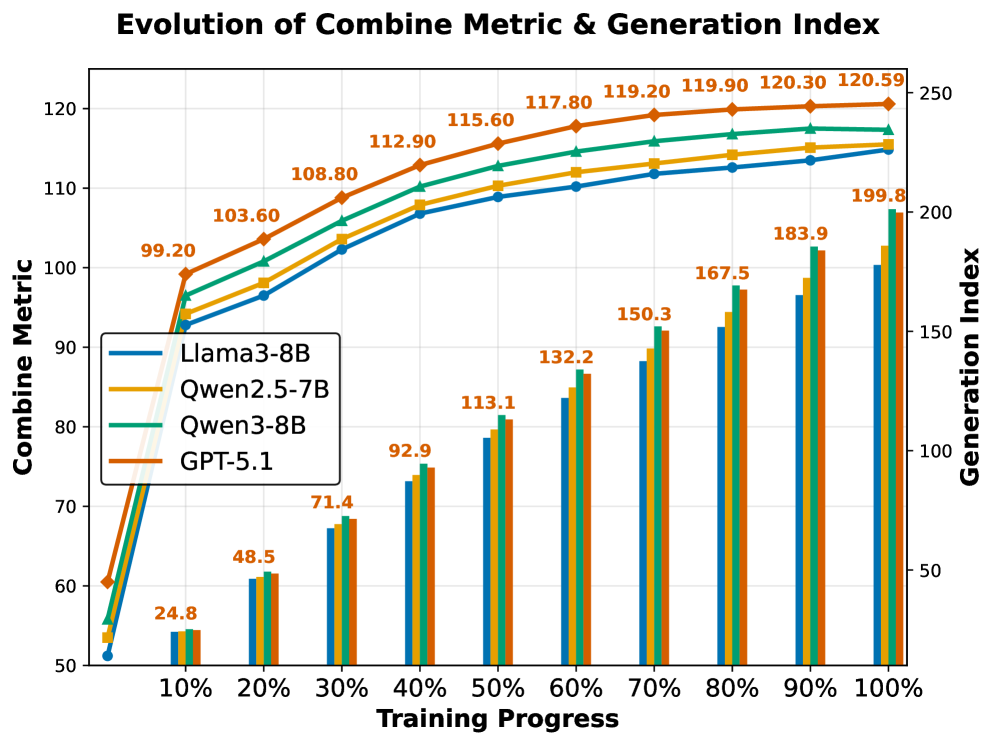
Fig 3: Figure 3: Combine metric evolution across generations on MultiWOZ 2.0. All backbones show monotonic improvement, and the rapid early gains reflect the exploration-exploitation trade-off inherent in evolutionary optimization.
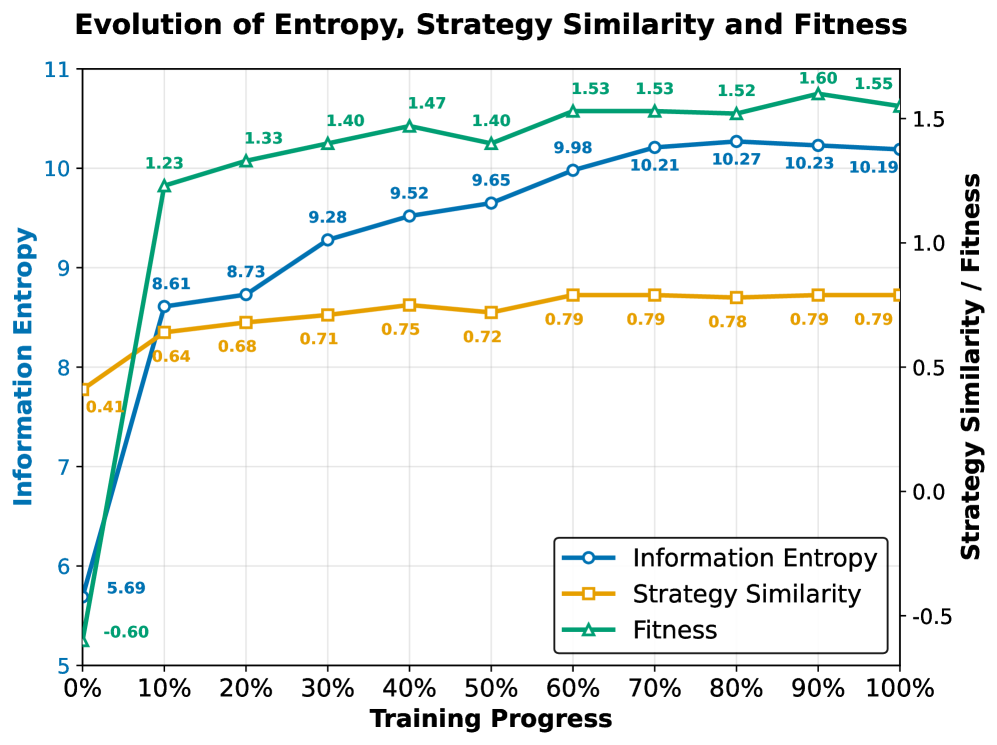
Fig 4: Figure 4: Evolutionary dynamics of ESB across generations on MultiWOZ 2.0 with Qwen3-8B. The simultaneous rise and subsequent decline of entropy and fitness, coupled with increasing pairwise similarity, demonstrates a self organizing transition from exploratory diversity to exploitative convergence.
Ready to evaluate your AI agents?
Learn how ReputAgent helps teams build trustworthy AI through systematic evaluation.
Learn MoreKeep in Mind
Results were measured mainly on simulated benchmarks (MultiWOZ and SGD), so real-world integration with live APIs and external tools will need extra engineering. The approach relies on running many strategies and offline evolution, which adds compute and requires careful cost/latency planning. Ongoing monitoring is needed to catch rare failure modes or undesired behavior as the system evolves in the wild. Agent
Deep Dive
DarwinTOD treats dialog strategies as a living population. During live conversations it selects strategies from an Evolvable Strategy Bank using a fitness-weighted probabilistic rule, lets multiple agent roles (understanding, policy, generation) interact and critique each other, and logs results. After each episode it runs an offline evolutionary cycle (generate, mutate, consolidate, prune) using accumulated feedback; strategies gain or lose fitness based on successes, peer critiques, usage counts, and an age penalty to keep diversity. The system design emphasizes practicality: powerful language models can be reserved for the offline evolution step while lighter agents run live, giving a cost-performance trade-off. Experiments show monotonic improvements across generations, robustness to weak initial strategy seeds, and sensitivity to a single, interpretable exploration parameter. Across MultiWOZ variants and the SGD benchmark DarwinTOD outperforms prior state-of-the-art, and ablations show the dual-loop architecture and peer critique are key to preventing cascading errors and driving targeted improvements. For deployment, the framework still needs stronger real-world tool integration and runtime safety monitoring, but it offers a clear path toward conversational agents that continuously improve themselves. Tree of Thoughts Pattern LLM-as-Judge
Explore evaluation patternsSee how to apply these findings
Credibility Assessment:
No affiliation or notable h-index signals; arXiv preprint with no citations.